Apache Kafka
Table of Contents
- 1. はじめよう
- 2. API
- 3. 設定
- 3.1. ブローカ設定
broker.idlog.dirsportzookeeper.connectmessage.max.bytesnum.network.threadsnum.io.threadsbackground.threadsqueued.max.requestshost.nameadvertised.host.nameadvertised.portsocket.send.buffer.bytessocket.receive.buffer.bytessocket.request.max.bytesnum.partitionslog.segment.byteslog.roll.{ms,hours}log.cleanup.policylog.retention.{ms,minutes,hours}log.retention.byteslog.retention.check.interval.mslog.cleaner.enablelog.cleaner.threadslog.cleaner.io.max.bytes.per.secondlog.cleaner.dedupe.buffer.sizelog.cleaner.io.buffer.sizelog.cleaner.io.buffer.load.factorlog.cleaner.backoff.mslog.cleaner.min.cleanable.ratiolog.cleaner.delete.retention.mslog.index.size.max.byteslog.index.interval.byteslog.flush.interval.messageslog.flush.scheduler.interval.mslog.flush.interval.mslog.delete.delay.mslog.flush.offset.checkpoint.interval.mslog.segment.delete.delay.msauto.create.topics.enablecontroller.socket.timeout.mscontroller.message.queue.sizedefault.replication.factorreplica.lag.time.max.msreplica.lag.max.messagesreplica.socket.timeout.msreplica.socket.receive.buffer.bytesreplica.fetch.max.bytesreplica.fetch.wait.max.msreplica.fetch.min.bytesnum.replica.fetchersreplica.high.watermark.checkpoint.interval.msfetch.purgatory.purge.interval.requestsproducer.purgatory.purge.interval.requestszookeeper.session.timeout.mszookeeper.connection.timeout.mszookeeper.sync.time.mscontrolled.shutdown.enablecontrolled.shutdown.max.retriescontrolled.shutdown.retry.backoff.msauto.leader.rebalance.enableleader.imbalance.per.broker.percentageleader.imbalance.check.interval.secondsoffset.metadata.max.bytesmax.connections.per.ipmax.connections.per.ip.overridesconnections.max.idle.mslog.roll.jitter.{ms,hours}num.recovery.threads.per.data.dirunclean.leader.election.enabledelete.topic.enableoffsets.topic.num.partitionsoffsets.topic.retention.minutesoffsets.retention.check.interval.msoffsets.topic.replication.factoroffsets.topic.segment.bytesoffsets.load.buffer.sizeoffsets.commit.required.acksoffsets.commit.timeout.ms- Topic-level configuration
- 3.2. Consumer Configs
- group.id
- zookeeper.connect
- consumer.id
- socket.timeout.ms
- socket.receive.buffer.bytes
- fetch.message.max.bytes
- num.consumer.fetchers
- auto.commit.enable
- auto.commit.interval.ms
- queued.max.message.chunks
- rebalance.max.retries
- fetch.min.bytes
- fetch.wait.max.ms
- rebalance.backoff.ms
- refresh.leader.backoff.ms
- auto.offset.reset
- consumer.timeout.ms
- exclude.internal.topics
- partition.assignment.strategy
- client.id
- zookeeper.session.timeout.ms
- zookeeper.connection.timeout.ms
- zookeeper.sync.time.ms
- offsets.storage
- offsets.channel.backoff.ms
- offsets.channel.socket.timeout.ms
- offsets.commit.max.retries
- dual.commit.enabled
- partition.assignment.strategy
- 3.3. Producer Configs
- metadata.broker.list
- request.required.acks
- request.timeout.ms
- producer.type
- serializer.class
- key.serializer.class
- partitioner.class
- compression.codec
- compressed.topics
- message.send.max.retries
- retry.backoff.ms
- topic.metadata.refresh.interval.ms
- queue.buffering.max.ms
- queue.buffering.max.messages
- queue.enqueue.timeout.ms
- batch.num.messages
- send.buffer.bytes
- client.id
- 3.4. New Producer Configs
- bootstrap.servers
- acks
- buffer.memory
- compression.type
- retries
- batch.size
- client.id
- linger.ms
- max.request.size
- receive.buffer.bytes
- send.buffer.bytes
- timeout.ms
- block.on.buffer.full
- metadata.fetch.timeout.ms
- metadata.max.age.ms
- metric.reporters
- metrics.num.samples
- metrics.sample.window.ms
- reconnect.backoff.ms
- retry.backoff.ms
- 3.1. ブローカ設定
- 4. 設計
- 5. 実装
- 6. 運用
1 はじめよう
1.1 導入
▶ show original text
Getting Started
Introduction
Kafka is a distributed, partitioned, replicated commit log service. It provides the functionality of a messaging system, but with a unique design.
Kafka は分散し、分割され、複製されるコミットログサービスです。 メッセージングシステムの機能を提供しますが、その設計は独特なものです。
▶ show original text
What does all that mean?
つまり、どういうことでしょう?
▶ show original text
First let's review some basic messaging terminology:
- Kafka maintains feeds of messages in categories called topics.
- We'll call processes that publish messages to a Kafka topic producers.
- We'll call processes that subscribe to topics and process the feed of published messages consumers..
- Kafka is run as a cluster comprised of one or more servers each of which is called a broker.
So, at a high level, producers send messages over the network to the Kafka cluster which in turn serves them up to consumers like this:
はじめに、基本的なメッセージングの用語を確認しておきましょう:
- Kafka は トピック と呼ばれるカテゴリ毎にメッセージのフィードを保持しています
- Kafka のトピックに対してメッセージを発行するプロセスを プロデューサ と呼びます
- 複数のトピックを購読し、発行されたメッセージのフィードを処理するプロセスを コンシューマ と呼びます
- Kafka はひとつ以上の ブローカ と呼ばれるサーバで構成されるクラスタとして動作します
すなわち以下の図のように、高レベルな視点ではプロデューサ群がネットワーク上で Kafka クラスタにメッセージを送信し、 そのメッセージを順次コンシューマ群に向けて提供する、というように動作します:
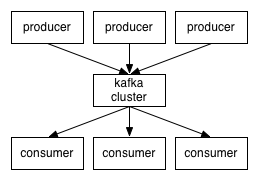
▶ show original text
Communication between the clients and the servers is done with a simple, high-performance, language agnostic TCP protocol. We provide a Java client for Kafka, but clients are available in many languages.
クライアントとサーバ間の通信はシンプルかつ高性能で、言語に依存しない TCP protocol で行なわれます。 提供されるのは Java の Kafka クライアントですが、 多くの言語で 利用することが出来ます。
トピックとログ
▶ show original text
Topics and Logs
Let's first dive into the high-level abstraction Kafka provides—the topic.
まず最初に、 Kafka が提供する高レベルな抽象概念である「トピック」について見ていきましょう。
▶ show original text
A topic is a category or feed name to which messages are published. For each topic, the Kafka cluster maintains a partitioned log that looks like this:
トピックはカテゴリ、あるいはフィードの名前であり、メッセージはトピックに対して発行されます。 以下の図のように、Kafka クラスタはトピックごとにログを分割して保持しています:
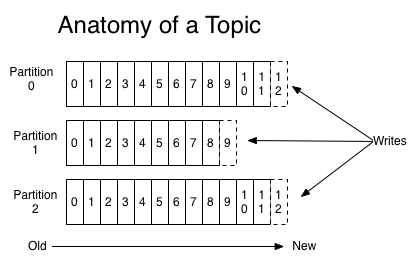
▶ show original text
Each partition is an ordered, immutable sequence of messages that is continually appended to—a commit log. The messages in the partitions are each assigned a sequential id number called the offset that uniquely identifies each message within the partition.
各パーティションは不変で順序があるメッセージ列で、メッセージは断続的に追記されます。 このメッセージ列を「コミットログ」と呼びます。 メッセージには、格納されたパーティションごとに「オフセット」と呼ばれるユニークな通し番号が付与されます。 このオフセットにより、パーティション内のメッセージを一意に特定することができます。
▶ show original text
The Kafka cluster retains all published messages—whether or not they have been consumed—for a configurable period of time. For example if the log retention is set to two days, then for the two days after a message is published it is available for consumption, after which it will be discarded to free up space. Kafka's performance is effectively constant with respect to data size so retaining lots of data is not a problem.
Kafka クラスタは、コンシュームされたかどうかに拘わらず、発行されたすべてのメッセージを保存しています。 保持する期間は設定で変更可能です。 例えばログ保存期間が2日間に設定されている場合、あるメッセージが発行されてから2日間はコンシューム可能ですが、 それ以降は容量確保のために破棄されます。 Kafkaの性能はデータサイズに関しては実質定数のため、大量のデータを保存することは問題ありません。
▶ show original text
In fact the only metadata retained on a per-consumer basis is the position of the consumer in the log, called the "offset". This offset is controlled by the consumer: normally a consumer will advance its offset linearly as it reads messages, but in fact the position is controlled by the consumer and it can consume messages in any order it likes. For example a consumer can reset to an older offset to reprocess.
実は、コンシューマ毎に保存されているメタデータというのは、ログ内のコンシューマの位置情報だけです。 これは「オフセット」と呼ばれます。 オフセットはコンシューマにより制御されます————通常はメッセージを読み進めるのに応じて順番にオフセットを進めますが、 オフセットの制御は実際のところコンシューマが行なうため、任意の順序でコンシュームすることが出来ます。 例えば、コンシューマは昔のオフセットにリセットして再処理を行なうことが出来ます。
▶ show original text
This combination of features means that Kafka consumers are very cheap—they can come and go without much impact on the cluster or on other consumers. For example, you can use our command line tools to "tail" the contents of any topic without changing what is consumed by any existing consumers.
以上の機能の組合せにより、Kafkaのコンシューマはとても安価であると言えます————コンシューマはクラスタへの参加・離脱を、 そのクラスタや、クラスタに所属する他のコンシューマに大きな影響を与えることなく行なうことができる、ということです。 例えば、任意のトピックについて、付属のコマンドラインツールで「tail」操作を行なうことが出来ますが、 これは既存のコンシューマのコンシューム状況を変えることなく行なうことが可能です。
▶ show original text
The partitions in the log serve several purposes. First, they allow the log to scale beyond a size that will fit on a single server. Each individual partition must fit on the servers that host it, but a topic may have many partitions so it can handle an arbitrary amount of data. Second they act as the unit of parallelism—more on that in a bit.
パーティションは様々な目的で提供されています。 第一に、ログを一台のサーバに収まりきらないサイズにまでスケールすることを可能にする目的です。 個々のパーティションについては、それを格納するサーバに収まるように調整する必要がありますが、 トピックは複数のパーティションに分割されるため、トピックのデータ量は無制限です。 第二に、パーティションは並行処理の単位としても利用されます————詳細は後述します。
分散
▶ show original text
Distribution The partitions of the log are distributed over the servers in the Kafka cluster with each server handling data and requests for a share of the partitions. Each partition is replicated across a configurable number of servers for fault tolerance.
ログのパーティションは Kafka クラスタ内のサーバ上で分散して保持されており、 各サーバはパーティションを共有するためのデータとリクエストを処理します。 耐障害性のために、各パーティションを複数のサーバに複製することも出来ます。 複製するサーバ数は設定で変更可能です。
▶ show original text
Each partition has one server which acts as the "leader" and zero or more servers which act as "followers". The leader handles all read and write requests for the partition while the followers passively replicate the leader. If the leader fails, one of the followers will automatically become the new leader. Each server acts as a leader for some of its partitions and a follower for others so load is well balanced within the cluster.
各パーティションは「リーダ」となる一つのサーバと、0以上の「フォロワ」サーバを持ちます。 リーダは担当のパーティションへの全ての読み書きリクエストを処理します。 対してフォロワは、リーダの複製を受動的に行ないます。 リーダに障害が発生した場合、フォロワのどれかが自動的に新たなリーダとなります。 各サーバはクラスタ内の負荷が均等になるように、自身のパーティションのうちいくつかのリーダとなり、 その他のパーティションのフォロワともなります。
プロデューサ
▶ show original text
Producers
Producers publish data to the topics of their choice. The producer is responsible for choosing which message to assign to which partition within the topic. This can be done in a round-robin fashion simply to balance load or it can be done according to some semantic partition function (say based on some key in the message). More on the use of partitioning in a second.
プロデューサは自身の選択したトピックに対してデータを発行します。 プロデューサはどのメッセージをトピック内のどのパーティションに割り当てるかを選択する責務があります。 これは負荷分散のためにラウンドロビン方式で選択することも出来ますし、 何らかの意味的な分割関数を利用することも出来ます(例えばメッセージの特定のキーを元に分割するなど)。 パーティションの利用に関する詳細は後述します。
コンシューマ
▶ show original text
Messaging traditionally has two models: queuing and publish-subscribe. In a queue, a pool of consumers may read from a server and each message goes to one of them; in publish-subscribe the message is broadcast to all consumers. Kafka offers a single consumer abstraction that generalizes both of these—the consumer group.
伝統的なメッセージングのモデルは キューイング と 出版・購読型 の二つです。 キューを用いる方法では、コンシューマプールがひとつのサーバからメッセージを取得することができ、 各メッセージはコンシューマのいずれか一つに渡ります。 一方の出版・購読型モデルでは、メッセージは全てのコンシューマにブロードキャストされます。 Kafka はその両方を一般化するコンシューマの抽象概念を提供しています。 それが「コンシューマグループ」です。
▶ show original text
Consumers label themselves with a consumer group name, and each message published to a topic is delivered to one consumer instance within each subscribing consumer group. Consumer instances can be in separate processes or on separate machines.
コンシューマは自分自身にコンシューマグループ名をラベル付けしており、 トピックに発行される各メッセージは、そのトピックを購読している各コンシューマグループそれぞれの、 ある一つのコンシューマインスタンスに対して屆けられます。 コンシューマインスタンスは異なるプロセス、あるいは異なるサーバ上で稼動させることが出来ます。
▶ show original text
If all the consumer instances have the same consumer group, then this works just like a traditional queue balancing load over the consumers.
全てのコンシューマインスタンスが同一のコンシューマグループに属しているならば、 コンシューマ上で負荷分散される伝統的なキューイングモデルのように動きます。
▶ show original text
If all the consumer instances have different consumer groups, then this works like publish-subscribe and all messages are broadcast to all consumers.
全てのコンシューマインスタンスがそれぞれ異なるコンシューマグループに属しているならば、 出版・購読型モデルのように動き、メッセージは全てのコンシューマにブロードキャストされることになります。
▶ show original text
More commonly, however, we have found that topics have a small number of consumer groups, one for each "logical subscriber". Each group is composed of many consumer instances for scalability and fault tolerance. This is nothing more than publish-subscribe semantics where the subscriber is cluster of consumers instead of a single process.
しかしより一般には、トピックは「論理的な購読者」を表す少数のコンシューマグループを持つことになるでしょう。 各グループはスケーラビリティと耐障害性のため、複数のコンシューマインスタンスで構成されます。 これは購読者が単一のプロセスではなく、コンシューマのクラスタとなっている出版・購読型モデルそのものです。
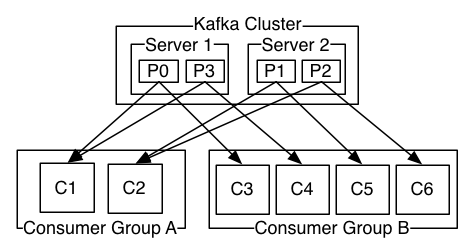
Figure 3: 4つのパーティション(P0-P3)をホスティングする2つのサーバで構成されるKafka クラスタ、及び2つのコンシューマグループ。グループAは2つ、Bは4つのインスタンスを持っている。
▶ show original text
Caption: A two server Kafka cluster hosting four partitions (P0-P3) with two consumer groups. Consumer group A has two consumer instances and group B has four.
Kafka has stronger ordering guarantees than a traditional messaging system, too.
また、Kafkaは伝統的なメッセージングシステムと比べてより強力な順序保証を提供しています。
▶ show original text
A traditional queue retains messages in-order on the server, and if multiple consumers consume from the queue then the server hands out messages in the order they are stored. However, although the server hands out messages in order, the messages are delivered asynchronously to consumers, so they may arrive out of order on different consumers. This effectively means the ordering of the messages is lost in the presence of parallel consumption. Messaging systems often work around this by having a notion of "exclusive consumer" that allows only one process to consume from a queue, but of course this means that there is no parallelism in processing.
伝統的なキューはメッセージを順番にサーバ上に保存しています。 複数のコンシューマがそのキューからコンシュームした場合、 サーバは保存されている順番にメッセージを取り出すでしょう。 しかし、サーバがメッセージを順番に取り出したところで、 コンシューマへのメッセージの配信は非同期に行われるため、 異なるコンシューマ間のメッセージ到達順序は狂う可能性があります。 つまり、コンシューマを並列に動かすような状況では、メッセージの順序は失われる、ということです。 メッセージングシステムはしばしば「排他的コンシューマ」という概念を利用して問題を回避しようとします。 ひとつのキューに対してただひとつプロセスのみコンシューム可能とする、というものです。 しかしこれは当然、並列処理は出来ません。
▶ show original text
Kafka does it better. By having a notion of parallelism—the partition—within the topics, Kafka is able to provide both ordering guarantees and load balancing over a pool of consumer processes. This is achieved by assigning the partitions in the topic to the consumers in the consumer group so that each partition is consumed by exactly one consumer in the group. By doing this we ensure that the consumer is the only reader of that partition and consumes the data in order. Since there are many partitions this still balances the load over many consumer instances. Note however that there cannot be more consumer instances than partitions.
Kafka はもっと上手いことやっています。 トピック内の並列性(これはつまり、パーティションのことです)という概念を利用することで、 Kafkaはコンシューマプロセスプール上の順序保証と負荷分散の両方を提供することが出来ます。 これは、各パーティションがグループ内のただ一つのコンシューマにのみコンシュームされるように、 トピック内のパーティションをコンシューマグループ内のコンシューマに割り当てることで実現されています。 これによって、パーティションを読むのはある特定コンシューマだけであることと、順序通りコンシュームすることが保証されます。 多くのパーティションがある為、これでもコンシューマインスタンス間の負荷は分散します。 ただし、パーティション数以上のコンシューマインスタンスは存在し得ないことに注意してください。
▶ show original text
Kafka only provides a total order over messages within a partition, not between different partitions in a topic. Per-partition ordering combined with the ability to partition data by key is sufficient for most applications. However, if you require a total order over messages this can be achieved with a topic that has only one partition, though this will mean only one consumer process.
Kafka はトピック内のパーティションの 中の メッセージ順序しか保証しません。 異なるパーティション間の順序は保証されません。 ほとんどのアプリケーションは、パーティション毎の順序とキー毎の分割機能との組み合わせで十分でしょう。 もし、全メッセージの順序が必要な場合は、パーティションひとつだけからなるトピックを使うことで実現出来ますが、 この場合コンシューマプロセスもただ一つのみになります。
保証
▶ show original text
Guarantees
At a high-level Kafka gives the following guarantees:
- Messages sent by a producer to a particular topic partition will be appended in the order they are sent. That is, if a message M1 is sent by the same producer as a message M2, and M1 is sent first, then M1 will have a lower offset than M2 and appear earlier in the log.
- A consumer instance sees messages in the order they are stored in the log.
- For a topic with replication factor N, we will tolerate up to N-1 server failures without losing any messages committed to the log.
More details on these guarantees are given in the design section of the documentation.
高レベルな視点では Kafka は以下の保証を提供します:
- プロデューサから特定のトピックパーティションへと送られたメッセージは、送られた順に追記されます。
つまり、メッセージ
M1とM2が同じプロデューサから送られ、かつM1が最初に送られていた場合、M1はM2よりも小さいオフセットを持ち、M2よりも先にログに現れます。 - コンシューマインスタンスはログに保存されている順番にメッセージを読みます。
- レプリケーションファクタ
Nに設定されたトピックは、N-1個までのサーバ障害については、 メッセージのロスト無く稼動することが出来ます。
これらの保証のより詳細については、本ドキュメントの設計セクションで述べられています。
1.2 ユースケース
▶ show original text
Use Cases
Here is a description of a few of the popular use cases for Apache Kafka. For an overview of a number of these areas in action, see this blog post.
Apache Kafka のユースケースをいくつか紹介します。 これらの分野についての数多くの取り組みの概要が このブログ記事 にまとめられています。
メッセージング
▶ show original text
Messaging
Kafka works well as a replacement for a more traditional message broker. Message brokers are used for a variety of reasons (to decouple processing from data producers, to buffer unprocessed messages, etc). In comparison to most messaging systems Kafka has better throughput, built-in partitioning, replication, and fault-tolerance which makes it a good solution for large scale message processing applications.
Kafka は伝統的なメッセージブローカの代替として使うことが出来ます。 メッセージブローカを利用する理由は様々です—— データ生成と処理を疎結合にする為、未処理のメッセージをバッファするため、等。 ほとんどのメッセージングシステムと比較して、 Kafka はより良いスループット、組込みのパーティショニング、複製、耐障害性を備えており、 大規模メッセージ処理アプリケーションの良いソリューションとなります。
▶ show original text
In our experience messaging uses are often comparatively low-throughput, but may require low end-to-end latency and often depend on the strong durability guarantees Kafka provides.
経験上、メッセージングは比較的低いスループットで、しかしエンドツーエンドの低いレイテンシを要求し、 また、Kafka が提供する強い堅牢性に関する保証に依存するという場合が多いです。
▶ show original text
このドメインでは、 ActiveMQ や RabbitMQ のような伝統的なメッセージングシステムと Kafka を比較することが出来ます。
Web サイトのアクティビティトラッキング
▶ show original text
Website Activity Tracking
The original use case for Kafka was to be able to rebuild a user activity tracking pipeline as a set of real-time publish-subscribe feeds. This means site activity (page views, searches, or other actions users may take) is published to central topics with one topic per activity type. These feeds are available for subscription for a range of use cases including real-time processing, real-time monitoring, and loading into Hadoop or offline data warehousing systems for offline processing and reporting.
ユーザ動向追跡パイプラインを、リアルタイムな Pub-Sub フィードの集合として再構築する、というのが Kafka の元々のユースケースでした。 つまり、サイトアクティビティ(ページビュー、検索等のユーザが取り得る行動)はアクティビティの種別毎にトピック分けされて、 中央に集められるということです。 これらのフィードは幅広いユースケースで利用することが出来ます。 リアルタイム処理やリアルタイム監視のために使われたり、 オフラインでの処理やレポートで利用するために Hadoop やオフラインのデータウェアハウジングシステムへ保存するために使われたりします。
▶ show original text
Activity tracking is often very high volume as many activity messages are generated for each user page view.
アクティビティトラッキングは各ユーザのページビューごとに大量のアクティビティメッセージが生成されるため、 しばしば超大容量のログを扱うことになります。
メトリクス
▶ show original text
Metrics
Kafka is often used for operational monitoring data. This involves aggregating statistics from distributed applications to produce centralized feeds of operational data.
Kafka は運用監視データとしても使われることがあります。 この場合は、運用データの中央フィードを生成するため、分散したアプリケーションの統計を集約するのに用いられます。
ログ集約
▶ show original text
Log Aggregation
Many people use Kafka as a replacement for a log aggregation solution. Log aggregation typically collects physical log files off servers and puts them in a central place (a file server or HDFS perhaps) for processing. Kafka abstracts away the details of files and gives a cleaner abstraction of log or event data as a stream of messages. This allows for lower-latency processing and easier support for multiple data sources and distributed data consumption. In comparison to log-centric systems like Scribe or Flume, Kafka offers equally good performance, stronger durability guarantees due to replication, and much lower end-to-end latency.
ログ集約ソリューションの代替として Kafka を利用する場合も多いです。 典型的なログ集約では、物理ログファイルをサーバから収集し、 ファイルサーバや HDFS のような中央ストレージに配置して処理されます。 Kafka はファイルの詳細について抽象化し、 また、ログやイベントデータをメッセージストリームとしてきれいに抽象化しています。 これにより、より低レイテンシで処理でき、また複数のデータソースや分散データ処理への対応が容易になります。 Scribe や Flume といったログ集約システムと比較して、 Kafka や同等のパフォーマンスと、複製によるより強い堅牢性保証、 及びエンドツーエンドのより低いレイテンシを提供します。
ストリーム処理
▶ show original text
Stream Processing Many users end up doing stage-wise processing of data where data is consumed from topics of raw data and then aggregated, enriched, or otherwise transformed into new Kafka topics for further consumption. For example a processing flow for article recommendation might crawl article content from RSS feeds and publish it to an "articles" topic; further processing might help normalize or deduplicate this content to a topic of cleaned article content; a final stage might attempt to match this content to users. This creates a graph of real-time data flow out of the individual topics. Storm and Samza are popular frameworks for implementing these kinds of transformations.
多くのユーザは段階的なデータ処理をすることになります。 データは生データのトピックからコンシュームされ、集約され、肉付けされ、 あるいはさらなるコンシュームの為に新たな Kafka トピックへの変換されます。 例えば記事レコメンドの処理フローは次のようなものになるでしょう: まず、RSS フィードから記事をクロールし、「記事」トピックに発行します。 続いて、内容を正規化したり重複を除いて、「クリーンな記事内容」トピックに発行します。 最後に、記事内容とユーザのマッチングを行ないます。 このような処理のフローは、個々のトピックから始まるリアルタイムデータフローのグラフを形成します。 Storm や Samza はこのような類の変換を行なうための有名なフレームワークです。
イベントソーシング
▶ show original text
Event Sourcing
Event sourcing is a style of application design where state changes are logged as a time-ordered sequence of records. Kafka's support for very large stored log data makes it an excellent backend for an application built in this style.
イベントソーシング はアプリケーション設計手法のひとつで、 状態の変更が時系列順のレコード列として記録されるというものです。 Kafka は超巨大なログデータを扱えるため、 この手法で構築されたアプリケーションの優れたバックエンドとして利用することが出来ます。
コミットログ
▶ show original text
Commit Log Kafka can serve as a kind of external commit-log for a distributed system. The log helps replicate data between nodes and acts as a re-syncing mechanism for failed nodes to restore their data. The log compaction feature in Kafka helps support this usage. In this usage Kafka is similar to Apache BookKeeper project.
Kafka を分散システムのための外部コミットログとして使うこともできます。 ノード間でデータを複製したり、障害ノードの復旧のための再同期機構として、このログを利用することが出来ます。 Kafka の ログコンパクション 機能もこの用途に適しています。 この用途では、Kafka と Apache BookKeeper プロジェクトは似ています。
1.3 クイックスタート
▶ show original text
This tutorial assumes you are starting fresh and have no existing Kafka or ZooKeeper data.
このチュートリアルは、まっさらな環境で、KafkaやZooKeeperが一切稼動していない前提で進めます。
ステップ 1: コードのダウンロード
ステップ 2: サーバの起動
▶ show original text
Step 2: Start the server
Kafka uses ZooKeeper so you need to first start a ZooKeeper server if you don't already have one. You can use the convenience script packaged with kafka to get a quick-and-dirty single-node ZooKeeper instance.
Kafka は ZooKeeper を使うため、まずは ZooKeeper サーバを起動する必要があります。 既に起動している ZooKeeper サーバがある場合は、新たに起動する必要はありません。 新たに起動する場合は、 Kafka に同梱されている便利スクリプトを使ってください。 このスクリプトは、単一ノードを手早く作るための適当なものです。
> bin/zookeeper-server-start.sh config/zookeeper.properties [2013-04-22 15:01:37,495] INFO Reading configuration from: config/zookeeper.properties (org.apache.zookeeper.server.quorum.QuorumPeerConfig) ...
▶ show original text
Now start the Kafka server:
では、 Kafka サーバを起動しましょう:
> bin/kafka-server-start.sh config/server.properties [2013-04-22 15:01:47,028] INFO Verifying properties (kafka.utils.VerifiableProperties) [2013-04-22 15:01:47,051] INFO Property socket.send.buffer.bytes is overridden to 1048576 (kafka.utils.VerifiableProperties) ...
ステップ 3: トピックの作成
▶ show original text
Step 3: Create a topic
Let's create a topic named "test" with a single partition and only one replica:
今度は「test」という名前の、単一パーティションで、複製を作らないトピックを作成してみましょう:
> bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
▶ show original text
We can now see that topic if we run the list topic command:
list コマンドで、作成したトピックを参照できるようになるはずです:
> bin/kafka-topics.sh --list --zookeeper localhost:2181 test
▶ show original text
Alternatively, instead of manually creating topics you can also configure your brokers to auto-create topics when a non-existent topic is published to.
また、手動でトピックを作成するのではなく、存在しないトピックへパブリッシュされた場合に自動で作成するようにブローカを設定することもできます。
ステップ 4: メッセージを送ってみる
▶ show original text
Step 4: Send some messages
Kafka comes with a command line client that will take input from a file or from standard input and send it out as messages to the Kafka cluster. By default each line will be sent as a separate message.
Kafka にはファイルか標準入力から Kafka クラスタにメッセージを送信出来るコマンドラインのクライアントが同梱されています。 デフォルトでは、各行がそれぞれ異なるメッセージとして送信されます。
▶ show original text
Run the producer and then type a few messages into the console to send to the server.
プロデューサスクリプトを起動し、コンソールにメッセージを打ちこんでサーバに送信してみましょう。 1
> bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test [2015-05-15 19:45:39,512] WARN Property topic is not valid (kafka.utils.VerifiableProperties) これはメッセージです これは別のメッセージです ^D
ステップ 5: コンシューマを起動する
▶ show original text
Kafka also has a command line consumer that will dump out messages to standard output.
Kafka にはメッセージを標準出力にダンプするコマンドラインのコンシューマも付属しています。
> bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning これはメッセージです これも別のメッセージです ^CConsumed 2 messages
▶ show original text
If you have each of the above commands running in a different terminal then you should now be able to type messages into the producer terminal and see them appear in the consumer terminal.
別々のターミナルで上記の両方のコマンドを実行すれば、プロデューサのターミナルでメッセージを打ち込むと、 コンシューマのターミナルでそれを確認することが出来ます。
▶ show original text
All of the command line tools have additional options; running the command with no arguments will display usage information documenting them in more detail.
全てのコマンドラインツールには追加のオプションがあります。 引数なしでコマンドを実行すると、より詳細が参照出来る使い方のドキュメントが出力されます。
ステップ 6: マルチブローカクラスタを立ち上げる
▶ show original text
Step 6: Setting up a multi-broker cluster
So far we have been running against a single broker, but that's no fun. For Kafka, a single broker is just a cluster of size one, so nothing much changes other than starting a few more broker instances. But just to get feel for it, let's expand our cluster to three nodes (still all on our local machine).
ここまでは、単一のブローカ上で動作させて決ましたが、これではあまり面白くないですね。 単一のブローカというのは Kafka にとってはサイズ1のクラスタに過ぎないので、 複数のブローカインスタンスを起動することもそれほど違いはありません。 ですが、感覚を掴む為に3ノードのクラスタに拡張してみましょう(とはいえ、まだ全てのノードは同じローカルマシン上です)。
▶ show original text
First we make a config file for each of the brokers:
まず、各ブローカ用の設定ファイルを作ります:
> cp config/server.properties config/server-1.properties > cp config/server.properties config/server-2.properties
▶ show original text
Now edit these new files and set the following properties:
続いて、これらのファイルを編集して、以下のプロパティを設定します:
config/server-1.properties:
broker.id=1
port=9093
log.dirs=/tmp/kafka-logs-1
config/server-2.properties:
broker.id=2
port=9094
log.dirs=/tmp/kafka-logs-2
▶ show original text
The broker.id property is the unique and permanent name of each node in the cluster. We have to override the port and log directory only because we are running these all on the same machine and we want to keep the brokers from all trying to register on the same port or overwrite each others data.
broker.id は、各ノードのクラスタ内でユニークな、永続的な名前を表すプロパティです。
ポート番号とログディレクトリだけは変更が必要です。
いま、これらのブローカは全て同一のマシン上で稼動しているので、
同じポート番号に登録しようとしたり、お互いのデータを上書きしあったりしてしまわないようにする必要があるためです。
▶ show original text
We already have Zookeeper and our single node started, so we just need to start the two new nodes:
既に ZooKeeper と単一ノードは起動しているので、3ノードのクラスタにするには、新しく2つのノードを立ち上げるだけです:
> bin/kafka-server-start.sh config/server-1.properties > /dev/null 2>&1 & ... > bin/kafka-server-start.sh config/server-2.properties > /dev/null 2>&1 & ...
▶ show original text
Now create a new topic with a replication factor of three:
では、レプリケーションファクタ3のトピックを作成してみます:
> bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 1 --topic my-replicated-topic
▶ show original text
Okay but now that we have a cluster how can we know which broker is doing what? To see that run the "describe topics" command:
出来ました、が、クラスタ上のブローカの状態を見るにはどうすればよいのでしょう? その為には "describe topics" コマンドを実行します:
> bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic my-replicated-topic Topic:my-replicated-topic PartitionCount:1 ReplicationFactor:3 Configs: Topic: my-replicated-topic Partition: 0 Leader: 1 Replicas: 1,2,0 Isr: 1,2,0
▶ show original text
Here is an explanation of output. The first line gives a summary of all the partitions, each additional line gives information about one partition. Since we have only one partition for this topic there is only one line.
出力内容の説明をします。 最初の行が全パーティションの要約で、続く各行がそれぞれ1パーティションの情報を表します。 このトピックにはパーティションが一つしかないので、出力は1行しかありません。
▶ show original text
- "leader" is the node responsible for all reads and writes for the given partition. Each node will be the leader for a randomly selected portion of the partitions.
- "replicas" is the list of nodes that replicate the log for this partition regardless of whether they are the leader or even if they are currently alive.
- "isr" is the set of "in-sync" replicas. This is the subset of the replicas list that is currently alive and caught-up to the leader.
Leaderはそのパーティションの全読み書きの責務を負うノードです。各ノードは、ランダムに選択されたパーティションのリーダになり得ますReplicasはこのパーティションのログを複製しているノードのリストです。リーダか否か、現在生存しているノードかどうかにはかかわらず表示されますIsrは「同期中」の複製を表します。Replicasのリストのうち、現在生存しており、リーダに追い付いているノードが表示されます
▶ show original text
Note that in my example node 1 is the leader for the only partition of the topic.
この例では、ノード1はこのトピックの唯一のパーティションのリーダであることに着目してください。
▶ show original text
We can run the same command on the original topic we created to see where it is:
同じコマンドを最初に作ったトピックについて実行して、ブローカの状況を見てみましょう:
> bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic test Topic:test PartitionCount:1 ReplicationFactor:1 Configs: Topic: test Partition: 0 Leader: 0 Replicas: 0 Isr: 0
▶ show original text
So there is no surprise there—the original topic has no replicas and is on server 0, the only server in our cluster when we created it.
特に変わったところはありません——このトピックは複製を一切持たず、元々クラスタを作成したときの唯一のノードである server 0 上にあります。
▶ show original text
Let's publish a few messages to our new topic:
さて、新しく作った方のトピックにいくつかメッセージをパブリッシュしてみましょう:
> bin/kafka-console-producer.sh --broker-list localhost:9092 --topic my-replicated-topic ... my test message 1 my test message 2 ^D
▶ show original text
Now let's consume these messages:
続いてこれらのメッセージをコンシュームします:
> bin/kafka-console-consumer.sh --zookeeper localhost:2181 --from-beginning --topic my-replicated-topic ... my test message 1 my test message 2 ^C
▶ show original text
Now let's test out fault-tolerance. Broker 1 was acting as the leader so let's kill it:
ここで、耐障害性のテストをしてみましょう。 今はブローカ1がリーダなので、こいつを殺しましょう:
> ps | grep server-1.properties 7564 ttys002 0:15.91 /System/Library/Frameworks/JavaVM.framework/Versions/1.6/Home/bin/java... > kill -9 7564
▶ show original text
Leadership has switched to one of the slaves and node 1 is no longer in the in-sync replica set:
リーダシップがスレーブノードの1つに移され、ノード1は Isr から外れます:
> bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic my-replicated-topic Topic:my-replicated-topic PartitionCount:1 ReplicationFactor:3 Configs: Topic: my-replicated-topic Partition: 0 Leader: 2 Replicas: 1,2,0 Isr: 2,0
▶ show original text
But the messages are still be available for consumption even though the leader that took the writes originally is down:
元々の書き込みを引き受けたリーダがダウンしているにもかかわらず、なおメッセージはコンシューム可能です。
> bin/kafka-console-consumer.sh --zookeeper localhost:2181 --from-beginning --topic my-replicated-topic ... my test message 1 my test message 2 ^C
1.4 エコシステム
▶ show original text
Ecosystem
There are a plethora of tools that integrate with Kafka outside the main distribution. The ecosystem page lists many of these, including stream processing systems, Hadoop integration, monitoring, and deployment tools.
メインディストリビューション外にも、Kafka 関連のツールが大量にあります。 エコシステムのページ に、ストリームプロセッシングシステムやHadoopとの統合、モニタリング、デプロイ等、 それらのツールの多くが列挙されています。
1.5 以前のバージョンからのアップグレード
▶ show original text
Upgrading From Previous Versions
0.8.1 から 0.8.2.0 へのアップグレード
▶ show original text
Upgrading from 0.8.1 to 0.8.2.0
0.8.2.0 is fully compatible with 0.8.1. The upgrade can be done one broker at a time by simply bringing it down, updating the code, and restarting it.
0.8.2.0 は 0.8.1 と完全に互換性があります。 単純に1台ずつブローカ停止し、コードを更新し、再起動することでアップグレード出来ます。
0.8.0 から 0.8.1 へのアップグレード
▶ show original text
Upgrading from 0.8.0 to 0.8.1
0.8.1 is fully compatible with 0.8. The upgrade can be done one broker at a time by simply bringing it down, updating the code, and restarting it.
0.8.1 は 0.8 と完全に互換性があります。 単純に1台ずつブローカ停止し、コードを更新し、再起動することでアップグレード出来ます。
0.7 からのアップグレード
▶ show original text
Upgrading from 0.7
0.8, the release in which added replication, was our first backwards-incompatible release: major changes were made to the API, ZooKeeper data structures, and protocol, and configuration. The upgrade from 0.7 to 0.8.x requires a special tool for migration. This migration can be done without downtime.
レプリケーションが追加された 0.8 は、初めて後方互換性が失われたリリースでした。 API、 ZooKeeper のデータ構造、プロトコル、設定に主要な変更が入りました。 0.7 から 0.8.x へのアップグレードには、移行のための 特別なツール が必要です。 移行は無停止で行なうことが可能です。
2 API
現在 Kafka の JVM クライアントをリライト中です。 0.8.2 では、新規に書き直された Java プロデューサーが同梱されています。 次期リリースでは同様に Java コンシューマを含める予定です。 これらの新しいクライアントは既存の Scala クライアントを置き換えるものとなる見込みですが、 互換性のためにしばらくは共存することになります。 これらのクライアントは別のjarで提供され、最低限の依存関係だけが定義されています。 過去の Scala クライアントは、サーバと同じパッケージに同梱されていました。 2
2.1 プロデューサ API
0.8.2 では、新規開発には新しい Java プロデューサを使うことを強くお奨めします。 これは実稼動環境での試験が済んでおり、一般的に以前の Scala クライアントよりも高速で高機能です。 以下のように、クライアント jar への依存を maven の pom に指定することで利用できます:
<dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>0.8.2.0</version> </dependency>
使い方や使用例は javadoc に書かれています。
レガシーな Scala プロデューサ API についてもし興味があれば、 ここ を参照してください。
2.2 ハイレベルコンシューマ API
class Consumer { /** * ConsumerConnector の作成 * * @param config コンシューマの groupid と、 ZooKeeper との接続情報文字列 zookeeper.connect が、 * 最低限必要 */ public static kafka.javaapi.consumer.ConsumerConnector createJavaConsumerConnector(ConsumerConfig config); } /** * V: メッセージの型 * K: メッセージに関連付けられたオプショナルなキー */ public interface kafka.javaapi.consumer.ConsumerConnector { /** * トピック毎に <K,V> 型のメッセージストリームのリストを生成する。 * * @param topicCountMap (トピック, ストリーム数) の Map * @param keyDecoder バイト列の Message を K 型へ変換するデコーダ * @param valueDecoder バイト列の Message から V 型へ変換するデコーダ * @return (トピック, KafkaStream のリスト) の Map。 * リストの要素数はストリーム数となる。 * 各ストリームは (メッセージ, メタデータ) のペア (MessageAndMetadata) のイテレータをサポートする。 */ public <K,V> Map<String, List<KafkaStream<K,V>>> createMessageStreams(Map<String, Integer> topicCountMap, Decoder<K> keyDecoder, Decoder<V> valueDecoder); /** * デフォルトのデコーダでトピック毎のストリームのリストを作成する。 */ public Map<String, List<KafkaStream<byte[], byte[]>>> createMessageStreams(Map<String, Integer> topicCountMap); /** * ワイルドカードにマッチしたトピックのメッセージストリームのリストを作成する。 * * @param topicFilter どのトピックを購読するかを特定する TopicFilter * (ホワイトリスト方式かブラックリスト方式かを隠蔽している)。 * @param numStreams 返すメッセージストリームの数 * @param keyDecoder メッセージキーをデコードするデコーダ * @param valueDecoder メッセージ自身をデコードするデコーダ * @return KafkaStream のリスト。 * 各ストリームは MessageAndMetadata 要素のイテレータをサポートする。 */ public <K,V> List<KafkaStream<K,V>> createMessageStreamsByFilter(TopicFilter topicFilter, int numStreams, Decoder<K> keyDecoder, Decoder<V> valueDecoder); /** * デフォルトのデコーダでワイルドカードにマッチしたトピックのメッセージストリームのリストを作成する。 */ public List<KafkaStream<byte[], byte[]>> createMessageStreamsByFilter(TopicFilter topicFilter, int numStreams); /** * ワイルドカードにマッチしたトピックのメッセージストリームをデフォルトのデコーダで一つだけ作成する。 */ public List<KafkaStream<byte[], byte[]>> createMessageStreamsByFilter(TopicFilter topicFilter); /** * このコネクタで接続している全てのトピック/パーティションのオフセットをコミットする */ public void commitOffsets(); /** * コネクタをシャットダウンする */ public void shutdown(); }
ハイレベルコンシューマ API の使い方を習得するには、この例 を参照して下さい。
2.3 シンプルコンシューマ API
class kafka.javaapi.consumer.SimpleConsumer { /** * トピックからメッセージのセットを取得する。 * * @param 取得するトピック名、パーティション、開始バイトオフセット、最大バイトを指定するリクエスト * @return 取得したメッセージのセット */ public FetchResponse fetch(kafka.javaapi.FetchRequest request); /** * 複数トピックのメタデータを取得する。 * * @param 取得する versionId, clientId, topic のシーケンスを指定するリクエスト。 * @return リクエストされた各トピックのメタデータ。 */ public kafka.javaapi.TopicMetadataResponse send(kafka.javaapi.TopicMetadataRequest request); /** * 与えられた時刻より以前の(maxSize以下の)妥当なオフセットのリストを取得する。 */ public kafak.javaapi.OffsetResponse getOffsetsBefore(OffsetRequest request); /** * シンプルコンシューマをクローズする。 */ public void close(); }
ほとんどのアプリケーションはハイレベルコンシューマ API で十分でしょう。 ハイレベルコンシューマではまだ提供されていない機能を利用したいアプリケーションもあるかもしれません (例えば、 再起動時の初期オフセットを設定するなど)。 その場合は低レベルな SimpleConsumer Api を利用出来ます。 利用する際のロジックはより複雑になります。 こちら の例に従ってやってみてください。
2.4 Kafka Hadoop コンシューマ API
データを集約し Hadoop に保存する、水平スケールするソリューションを提供するというのは、基本的なユースケースでした。 このユースケースをサポートするため、 Kafka クラスタから並列にデータを取得する大量のマップタスクを起動させる、Hadoop ベースのコンシューマを提供しています。 これにより高速なプルペースの Hadoop データロードが実現できます (ごく少ない Kafka サーバだけでネットワーク帯域を完全に使い切ることが出来ていました)。
Hadoop コンシューマの使用方法は こちら です。
3 設定
Kafka は プロパティファイルフォーマット の key-value ペアで設定を行ないます。 これらの値はファイル、もしくはプログラム中で設定することが出来ます。
3.1 ブローカ設定
broker.id
| デフォルト |
各ブローカは非負整数の ID により一意に識別されます。 この ID はブローカの「名前」として使われ、 そのブローカが異なるホスト/ポートに移動した際にもコンシューマは混乱なく利用出来るようになります。
クラスタ内でユニークでありさえすれば任意の数値を設定できます。
log.dirs
| デフォルト | /tmp/kafka-logs |
Kafka のデータが保存される1つ以上のディレクトリです。 複数指定する際はカンマで区切って指定します。 新しく作られた各パーティションは、 その時点で保持しているパーティションが最も少ないディレクトリに配置されます。
port
| デフォルト | 9092 |
クライアントからの接続を受け付けるサーバのポート番号です。
zookeeper.connect
| デフォルト | null |
ZooKeeperとの接続情報を hostname:port という形式で文字列で指定します。
hostname 、 port はそれぞれ ZooKeeper クラスタに属するノードのホスト名とポート番号です。
hostname1:port1,hostname2:port2,hostname3:port3 のように複数のホストを指定することで、
ホストダウン時に他のZooKeeperノードへ接続出来るように出来ます。
ZooKeeper では "chroot" パスを追加することも出来、
これによってクラスタ内の全ての Kafka データが特定のパス以下に配置されるように設定出来ます。
こうすることで、異なる Kafka クラスタや他のアプリケーションを、同じ ZooKeeper クラスタ上に構築出来ます。
具体的には、 hostname1:port1,hostname2:port2,hostname3:port3/chroot/path のように指定することで、
全 Kafka クラスタのデータが /chroot/path 以下に配置されるように出来ます。
chroot を指定する場合、全コンシューマが同じ接続情報文字列を利用するようにしなければなりません。
message.max.bytes
| デフォルト | 1000000 |
サーバが受け取るメッセージの最大サイズです。 このプロパティは コンシューマが利用する最大取得サイズ設定 と同調して設定するよう注意しましょう。 さもなければ、乱暴なプロデューサがコンシューマが扱えない程のサイズのメッセージを パブリッシュすることが出来るようになってしまいます。
num.network.threads
| デフォルト | 3 |
サーバがネットワークリクエストを処理するのに使うネットワークスレッドの数です。 恐らく変更する必要はありません。
num.io.threads
| デフォルト | 8 |
サーバがリクエストを処理するために使う I/O スレッドの数です。 少なくとも利用するディスク数分は用意するべきです。
background.threads
| デフォルト | 10 |
ファイル削除のような様々なバックグラウンド処理を行なう為に使われるスレッドの数です。 変更する必要はないでしょう。
queued.max.requests
| デフォルト | 500 |
I/O スレッドが処理する為にキューに詰まれる最大リクエスト数で、 この数までキューに詰まれると、ネットワークスレッドは新規リクエストを読むのを止めます。
host.name
| デフォルト | null |
ブローカのホスト名です。 この値が設定されていれば、そのアドレスにだけバインドします。 設定されていなければ、全インタフェースにバインドします。 この情報は ZooKeeper にパブリッシュされクライアントから利用されます。
advertised.host.name
advertised.port
| デフォルト | null |
プロデューサやコンシューマ、そして他のブローカが接続するポート番号です。 サーバがバインドするポートと異なる場合のみ必要な設定です。
socket.send.buffer.bytes
| デフォルト | 100 * 1024 |
ソケット接続時にサーバが利用する SO_SNDBUFF バッファの値です。
socket.receive.buffer.bytes
| デフォルト | 100 * 1024 |
ソケット接続時にサーバが利用する SO_RCVBUFF バッファの値です。
socket.request.max.bytes
| デフォルト | 100 * 1024 * 1024 |
サーバが許容する最大リクエストサイズです。 メモリ不足に陥らないよう、 Java ヒープサイズよりも小さい値に設定すべきです。
num.partitions
| デフォルト | 1 |
トピック作成時に指定されなかった場合のデフォルトパーティション数です。
log.segment.bytes
| デフォルト | 1024 * 1024 * 1024 |
トピックパーティションのログは、セグメントファイルのディレクトリとして保存されています。 1セグメントのファイルサイズがこの値に達すると、新しいセグメントファイルが作成されます。 6 この設定値はトピック毎に上書き可能です( トピックレベルの設定 を参照)。
log.roll.{ms,hours}
| デフォルト | 24 * 7 hours |
セグメントファイルサイズが log.segment.bytes に到達していない場合でも、
この設定値の時間が経過した場合に強制的に新たなログセグメントを作成するよう設定します。
この設定値はトピック毎に上書き可能です( トピックレベルの設定 を参照)。
log.cleanup.policy
| デフォルト | delete |
delete または compact を設定出来ます。
ログセグメントがサイズや時間の上限に達した際に、
delete の場合は削除され、 compact の場合は ログコンパクション が行なわれます。
この設定値はトピック毎に上書き可能です( トピックレベルの設定 を参照)。
log.retention.{ms,minutes,hours}
| デフォルト | 7 days |
ログセグメントを削除するまでの時間、つまりトピックのデフォルト保持期間です。
log.retention.minutes と log.retention.bytes が両方セットされていた場合、
いずれかの上限に達した時点でクリーンアップを行ないます。
この設定値はトピック毎に上書き可能です( トピックレベルの設定 を参照)。
log.retention.bytes
| デフォルト | -1 |
各トピックパーティションログの総サイズ制限です。 これはパーティション毎の制限なので、トピックが必要とするトータルのデータ容量は、これにパーティション数を掛けた値になります。
log.retention.minutes と log.retention.bytes が両方セットされていた場合、
いずれかの上限に達した時点でクリーンアップを行ないます。
この設定値はトピック毎に上書き可能です( トピックレベルの設定 を参照)。
log.retention.check.interval.ms
| デフォルト | 5 minutes |
ログの保持ポリシーと照らし合わせて、削除対象となるログセグメントがあるかどうかを確認する間隔です。
log.cleaner.enable
| デフォルト | false |
ログコンパクションを実行するためには、この設定は必ず true にしなければなりません。
log.cleaner.threads
| デフォルト | 1 |
ログコンパクション実行時のログクリーニングに使われるスレッド数です。
log.cleaner.io.max.bytes.per.second
| デフォルト | Double.MaxValue |
ログクリーナがログコンパクション実行時に発生する I/O の最大総サイズです。 この制限を設けることで、クリーナが運用中のサービスに影響を与えることを避けることが出来ます。
log.cleaner.dedupe.buffer.size
| デフォルト | 500*1024*1024 |
ログクリーナがクリーニング中にインデクシングとログの重複除去のために使用するバッファサイズです。 十分なメモリがあるならば、より大きな値の方が望ましいです。
log.cleaner.io.buffer.size
| デフォルト | 512*1024 |
ログクリーニング中に使用される I/O チャンクのサイズです。 恐らく変更する必要はないでしょう。
log.cleaner.io.buffer.load.factor
| デフォルト | 0.9 |
ログクリーニング中に使用されるハッシュテーブルの load factor です。 恐らく変更する必要はないでしょう。
log.cleaner.backoff.ms
| デフォルト | 15000 |
クリーニングが必要なログが無いか確認する間隔です。
log.cleaner.min.cleanable.ratio
| デフォルト | 0.5 |
ログコンパクション が有効なときの、ログコンパクタがログをクリーンする頻度を設定します。 デフォルトでは50%以上のログがコンパクションされていた場合はクリーニングを行ないません。 この比率はログの重複により無駄に使用される最大スペースを設定します (50%だと、多くて50%のログが重複している可能性がある、ということです)。 より高い比率に設定すれば、少ない回数で、より効率的なクリーニングが行われることになりますが、 それは同時にログが無駄に使用するスペースがより多くなるということにもなります。 この設定値はトピック毎に上書き可能です( トピックレベルの設定 を参照)。
log.cleaner.delete.retention.ms
| デフォルト | 1 day |
ログコンパクション されたトピックの削除トゥームストーンマーカを保持する期間です。 最終段階の有効なスナップショットを確実に得る為にオフセット 0 から読み込みを開始する場合、 コンシューマはこの期間内に読み込みを完了させる必要があります (さもなければ、コンシューマの走査が完了する前に 削除トゥームストーンマーカが回収されてしまう可能性が有ります。)。 この設定値はトピック毎に上書き可能です( トピックレベルの設定 を参照)。
log.index.size.max.bytes
| デフォルト | 10 * 1024 * 1024 |
各ログセグメントのオフセットインデックスが使用する容量の最大バイト数です。
ここで設定した容量のスパースファイルを事前に確保して、
新たなログセグメント作成のタイミングで実容量まで縮める、という動作をする点に注意してください。
インデックスがいっぱいになってしまった場合は、
log.segment.bytes を超過していない場合でも新たなログセグメントを作成します。
この設定値はトピック毎に上書き可能です( トピックレベルの設定 を参照)。
log.index.interval.bytes
| デフォルト | 4096 |
オフセットインデックスにエントリを追加するバイト間隔です。
取得リクエストを実行する際、サーバは取得を開始、あるいは終了するために、
正しいログ内の位置を見つけるため、ここで設定したバイト数まで線形走査する必要があります。
そのためこの値を大きくすればする程インデックスファイルは大きくなり
(そしてもう少しだけメモリを使用するようになり)ますが、走査回数は少なくなります。
7
ただ、サーバはログ追加毎に2つ以上インデックスエントリを追加することは決してありません
(たとえ log.index.interval を上回るメッセージが追加されたとしても)。
普通はこの値をいじる必要は無いでしょう。
log.flush.interval.messages
| デフォルト | Long.MaxValue |
ここで設定された数までメッセージをログパーティションに書き込んだら、強制的にログを fsync します。 この値を小さくすれば頻繁にディスクにデータを同期するようになりますが、パフォーマンスに多大な影響を与えます。 耐久性を得るためには、単一サーバの fsync に依存するよりもレプリケーションを利用することを通常は推奨しますが、 さらなる確実性を求める場合はこの設定を利用することも出来ます。
log.flush.scheduler.interval.ms
| デフォルト | Long.MaxValue |
ログフラッシャがディスクにフラッシュするのに適したログがあるかをチェックする頻度をミリ秒で設定します.
log.flush.interval.ms
| デフォルト | Long.MaxValue |
ログの fsync がコールされるまでの最大時間です。
log.flush.interval.messages と合わせて設定された場合は、
どちらかの条件を満たした時点でログがフラッシュされます。
log.delete.delay.ms
| デフォルト | 60000 |
メモリ上のセグメントインデックスから除去された後にログファイルを保持しておく期間です。 この期間はロックせずとも進行中の読み込みを中断することなく完了することが出来ます。 8 通常はこの値を変更する必要は無いでしょう。
log.flush.offset.checkpoint.interval.ms
| デフォルト | 60000 |
リカバリのためにログの最終フラッシュのチェックポイントをセットする頻度です。 これは変更すべきではありません。
log.segment.delete.delay.ms
| デフォルト | 60000 |
ファイルシステムからログセグメントファイルを削除するまでの時間です。
auto.create.topics.enable
| デフォルト | true |
サーバに自動でトピックを作成可能にします。 この設定が有効な場合、存在しないトピックを作成、あるいはそのメタデータを取得しようとした際に、 デフォルトのレプリケーションファクタとパーティション数で自動的にトピックが作成されます。
controller.socket.timeout.ms
| デフォルト | 30000 |
レプリカに対するパーティション管理コントローラのソケットタイムアウトです。
controller.message.queue.size
| デフォルト | Int.MaxValue |
コントローラからブローカへの接続チャネル( controller-to-broker-channels )のバッファサイズです。
default.replication.factor
| デフォルト | 1 |
自動作成されたトピックのデフォルトレプリケーションファクタです。
replica.lag.time.max.ms
| デフォルト | 10000 |
フォロワがここで設定した時間内に取得リクエストを送信しなかった場合、 リーダはそのフォロワを ISR (in-sync replicas) から除去し、死んだものとして扱います。
replica.lag.max.messages
| デフォルト | 4000 |
ここで設定したメッセージ数よりレプリケーションが遅れた場合、 リーダはそのフォロワを ISR (in-sync replicas) から除去し、死んだものとして扱います。
replica.socket.timeout.ms
| デフォルト | 30 * 1000 |
データ複製の為のリーダへのネットワークリクエストのソケットタイムアウトです。
replica.socket.receive.buffer.bytes
| デフォルト | 64 * 1024 |
データ複製の為のリーダへのネットワークリクエストのソケット受信バッファです。
replica.fetch.max.bytes
| デフォルト | 1024 * 1024 |
レプリカがリーダへ送信する取得リクエスト時の、 各パーティションについて取得を試行するメッセージのバイト数です。
replica.fetch.wait.max.ms
| デフォルト | 500 |
レプリカがリーダへ送信する取得リクエスト時の、リーダへデータが到達するまでの待機時間です。
replica.fetch.min.bytes
| デフォルト | 1 |
レプリカがリーダへ送信する取得リクエストに対する各取得レスポンスが想定する最小バイトです。
この設定に満たない場合は、 replica.fetch.wait.max.ms まで待機します。
num.replica.fetchers
| デフォルト | 1 |
リーダからメッセージを複製するのに使うスレッド数です。 この設定値を増やすとフォロワブローカの I/O 並列処理数が増加します。
replica.high.watermark.checkpoint.interval.ms
| デフォルト | 5000 |
各レプリカがリカバリ処理の為に自身のハイウォータマークを記録する頻度です。
fetch.purgatory.purge.interval.requests
| デフォルト | 1000 |
取得リクエストパーガトリの 9 解放間隔(リクエスト数)です。
producer.purgatory.purge.interval.requests
| デフォルト | 1000 |
プロデューサリクエストパーガトリ 9 の解放間隔(リクエスト数)です。
zookeeper.session.timeout.ms
| デフォルト | 6000 |
ZooKeeper のセッションタイムアウトです。 ZooKeeperへのハートビートがこの期間失敗すると、そのサーバは死んだものとされます。 この値をあまりにも小さくしてしまうと、サーバが死んだと誤検知されてしまうかもしれませんし、 かといって大きくし過ぎると、本当に死んだサーバを認識するのに時間がかかるようになってしまいます。
zookeeper.connection.timeout.ms
| デフォルト | 6000 |
クライアントが ZooKeeper との接続を確立するまでの最大待機時間です。
zookeeper.sync.time.ms
| デフォルト | 2000 |
ZooKeeper フォロワがリーダからどのくらい遅れ得るかです。
controlled.shutdown.enable
| デフォルト | true |
ブローカの制御シャットダウンを有効にします。 この設定が有効な場合、そのブローカはシャットダウン前に自身のリーダ権を全て他のブローカに移動させます。 これによりシャットダウン中のサービス不能期間を減らすことが出来ます。
controlled.shutdown.max.retries
| デフォルト | 3 |
制御シャットダウンが成功するまでのリトライ回数です。 この回数を超えて失敗すると、強制シャットダウンされます。
controlled.shutdown.retry.backoff.ms
| デフォルト | 5000 |
シャットダウンのリトライ時のバックオフ時間です。
auto.leader.rebalance.enable
| デフォルト | true |
この設定が有効な場合、コントローラは自動的にブローカ間でパーティションのリーダ権のバランシングを試みます。 バランシングは、定期的にリーダ権を各パーティションの「優先」レプリカに返却することによって行なわれます(「推奨」レプリカが存在する場合)。
leader.imbalance.per.broker.percentage
| デフォルト | 10 |
リーダのブローカ毎の偏りのパーセンテージです。 コントローラはブローカ毎にこの割合を超えた場合にリーダ権のリバランスを行います。
leader.imbalance.check.interval.seconds
| デフォルト | 300 |
リーダの偏りを検査する頻度です。
offset.metadata.max.bytes
| デフォルト | 4096 |
クライアントが自身のオフセットを記録するためのメタデータの最大容量です。
max.connections.per.ip
| デフォルト | Int.MaxValue |
ブローカが IP 毎に許可する接続数の最大値です。
max.connections.per.ip.overrides
| デフォルト |
IP またはホスト名を指定して、デフォルトの最大接続数を上書き出来ます。
connections.max.idle.ms
| デフォルト | 600000 |
アイドルコネクションタイムアウト、つまり、 サーバソケットプロセッサスレッドがこの値以上アイドル状態だった場合に接続を閉じます。
log.roll.jitter.{ms,hours}
| デフォルト | 0 |
logRollTimeMillis から減じられる最大ジッタです。
num.recovery.threads.per.data.dir
| デフォルト | 1 |
データディレクトリ毎に起動時のログリカバリやシャットダウン時のフラッシュに使用されるスレッド数です。
unclean.leader.election.enable
| デフォルト | true |
最終手段として ISR 以外のレプリカをリーダとして選択することを許可するかどうかを示します。 これによりデータがロストする可能性があります。
delete.topic.enable
| デフォルト | false |
トピックを削除出来るようにします。
offsets.topic.num.partitions
| デフォルト | 50 |
オフセットコミットトピックのパーティション数です。 デプロイ後にこの値を変えることは現在サポートされていないため、 プロダクション環境ではより大きい数値(例えば 100-200)に設定することを推奨します。
offsets.topic.retention.minutes
| デフォルト | 1440 |
この値よりも古いオフセットは削除対象としてマークされます。 ログクリーナがオフセットトピックのコンパクションを実行した際に、実際に削除されます。
offsets.retention.check.interval.ms
| デフォルト | 600000 |
オフセットマネージャが古くなったオフセットを検査する頻度です。
offsets.topic.replication.factor
| デフォルト | 3 |
オフセットコミットトピックのレプリケーションファクタです。 高可用性を保証するにはこの値をより高い値(3や4等)に設定することを推奨します。 レプリケーションファクタよりも少ないブローカしかいな場合にオフセットトピックが作成された場合は、 この設定よりも少ないレプリカしか作られません。
offsets.topic.segment.bytes
| デフォルト | 104857600 |
オフセットトピックのセグメントサイズです。 オフセットトピックはコンパクションされたトピックを使う為、 ログコンパクションとロードを高速に行ない易くするためには この設定値は比較的小さな値にしておくべきです。
offsets.load.buffer.size
| デフォルト | 5242880 |
ブローカがあるコンシューマグループのオフセットマネージャになった時に (つまり、 オフセットトピックのリーダになった時に)、オフセットのロードが行なわれます。 オフセットマネージャのキャッシュにオフセットをロードする際に、 ここで設定したバッチサイズ(バイト数指定)を参照してオフセットセグメントからの読み込みを行ないます。
offsets.commit.required.acks
| デフォルト | -1 |
オフセットコミットが受け入れられる為に必要な Ack 数です。 プロデューサの Ack 設定と似たようなものです。 通常はデフォルト値から変更すべきではありません。
offsets.commit.timeout.ms
| デフォルト | 5000 |
このタイムアウト分か、必要なレプリカがオフセットコミットを受信するまでオフセットコミットは遅延されます。 プロデューサのリクエストタイムアウトと似たようなものです。
Topic-level configuration
トピック関連の設定には、
グローバルなデフォルト設定と、
トピック毎にオーバライドするための設定の二つが有ります。
トピック毎の設定が与えられなければグローバルデフォルト値が使用されます。
トピック作成時に一つ以上の --config オプションを与えることでオーバライド出来ます。
my-topic という名前のトピックを、
最大メッセージサイズとフラッシュレートをカスタマイズして作成する例を以下に示します:
> bin/kafka-topics.sh --zookeeper localhost:2181 --create --topic my-topic --partitions 1
--replication-factor 1 --config max.message.bytes=64000 --config flush.messages=1
オーバライドはオルター(変更)コマンドを利用することで後から変更・設定することも出来ます。 my-topic の最大メッセージサイズを更新する例を以下に示します:
> bin/kafka-topics.sh --zookeeper localhost:2181 --alter --topic my-topic --config max.message.bytes=128000
オーバライド設定を削除するには以下のようにします:
> bin/kafka-topics.sh --zookeeper localhost:2181 --alter --topic my-topic --deleteConfig max.message.bytes
以下はトピックレベルの設定です。 プロパティに対応するサーバのデフォルト設定は「サーバデフォルトプロパティ」の列にあります。 このサーバ設定を変更することで、オーバライド未指定時にトピックに設定されるデフォルト値を変更することが出来ます。
cleanup.policy
| デフォルト | delete |
| サーバデフォルトプロパティ | log.cleanup.policy |
delete または compact を設定出来ます。
古くなったログセグメントに適用される保持ポリシーを指定します。
デフォルトポリシー( delete )では、保持期限を過ぎるか容量制限に達した場合に、古いセグメントは破棄されます。
compact ポリシーではトピックに対して ログコンパクション が行われます。
delete.retention.ms
| デフォルト | 86400000 (24 時間) |
| サーバデフォルトプロパティ | log.cleaner.delete.retention.ms |
ログコンパクションされたトピックの削除トゥームストーンマーカを保持する時間です。
ログコンパクション されたトピックの削除トゥームストーンマーカを保持する期間です。 最終段階の有効なスナップショットを確実に得る為にオフセット 0 から読み込みを開始する場合、 コンシューマはこの期間内に読み込みを完了させる必要があります (さもなければ、コンシューマの走査が完了する前に 削除トゥームストーンマーカが回収されてしまう可能性が有ります。)。
flush.messages
| デフォルト | None |
| サーバデフォルトプロパティ | log.flush.interval.messages |
ログに書き込むデータをディスクに強制的に fsync するする間隔を指定出来ます。 例えば、この値を 1 にすると全メッセージについて都度 fsync するようになります; もし 5 にすると、5メッセージ毎に fsync を行うようになります。 通常はこの設定は指定せず、堅牢性は複製機構によって担保するようにすること推奨します。 オペレーティングシステムのより効率的なバックグラウンドのフラッシュ性能に委ねましょう。 この設定値はトピック毎に上書き可能です( トピックレベルの設定 を参照)。 10
flush.ms
| デフォルト | None |
| サーバデフォルトプロパティ | log.flush.interval.ms |
ログに書き込むデータをディスクに強制的に fsync するする間隔を指定出来ます。 例えば、この値を 1000 にすると 1000 ms 経過毎に fsync するようになります。 通常はこの設定は指定せず、堅牢性は複製機構によって担保するようにすること推奨します。 オペレーティングシステムのより効率的なバックグラウンドのフラッシュ性能に委ねましょう。
index.interval.bytes
| デフォルト | 4096 |
| サーバデフォルトプロパティ | log.index.interval.bytes |
この設定はKafkaがオフセットインデックスにインデックスエントリを追加する頻度を制御します。 デフォルト設定ではおよそ 4096 バイト毎にメッセージをインデックスするようになっています。 より多くインデクシングすればする程、 読み込み時にログ上の正確な位置を知ることが出来るようになりますが、 その分インデックスサイズは大きくなります。 おそらくこの値を変更する必要はないでしょう。
max.message.bytes
| デフォルト | 1,000,000 |
| サーバデフォルトプロパティ | message.max.bytes |
そのトピックに追記出来る最大メッセージサイズです。 この値を増やすならば、コンシューマの最大取得サイズも増やさなければ、 メッセージを取得出来なくなってしまうため注意が必要です。
min.cleanable.dirty.ratio
| デフォルト | 0.5 |
| サーバデフォルトプロパティ | log.cleaner.min.cleanable.ratio |
ログコンパクション が有効なときの、ログコンパクタがログをクリーンする頻度を設定します。 デフォルトでは50%以上のログがコンパクションされていた場合はクリーニングを行ないません。 この比率はログの重複により無駄に使用される最大スペースを設定します (50%だと、多くて50%のログが重複している可能性がある、ということです)。 より高い比率に設定すれば、少ない回数で、より効率的なクリーニングが行われることになりますが、 それは同時にログが無駄に使用するスペースがより多くなるということにもなります。 11
min.insync.replicas
| デフォルト | 1 |
| サーバデフォルトプロパティ | min.insync.replicas 12 |
プロデューサが request.required.acks を -1 に設定していた場合、
その書き込みが成功したと判断される為には、
最低限この設定値以上の複製が受領されなければなりません。
これが満たされない場合、プロデューサは例外を発生させます
( NotEnoughReplicas もしくは NotEnoughReplicasAfterAppend)。
min.insync.replicas と request.required.acks を共に設定することで、
より強力な堅牢性を保証することが出来ます。
典型的なシナリオでは、レプリケーションファクタ 3 のトピックを作成し、
min.insync.replicas を 2 に設定した上で、
request.required.acks を -1 に設定してプロデュースする、というようになるでしょう。
こうすることで、書込みを受領出来ない複製が多数を占めた場合に、
プロデューサが例外を投げることを保証出来ます。
retention.bytes
| デフォルト | None |
| サーバデフォルトプロパティ | log.retention.bytes |
ログの保持ポリシーが delete の場合に、
ログ容量がこの設定値を超えると、容量確保の為に古いログセグメントを破棄します。
デフォルトでは容量制限は無く、時間による制限のみです。
retention.ms
| デフォルト | 7 日 |
| サーバデフォルトプロパティ | log.retention.minutes |
ログの保持ポリシーが delete の場合に、
ログがこの設定値より古くなると、容量確保の為に古いログセグメントを破棄します。
これはコンシューマがデータを取得するまでの期間に関する
SLA(service level agreement, サービス品質保証)を表わしています。
segment.bytes
| デフォルト | 1 GB |
| サーバデフォルトプロパティ | log.segment.bytes |
ログのセグメントファイルサイズを制御します。 保持及びクリーニングは常に1ファイルごとに行なわれるため、 セグメントファイルサイズが大きくなれば扱うファイル数は少なくなりますが、 ファイル保持制御の粒度は荒くなってしまいます。
segment.index.bytes
| デフォルト | 10 MB |
| サーバデフォルトプロパティ | log.index.size.max.bytes |
オフセットとファイルの位置を対応づけるインデックスのサイズを制御します。 このインデックスファイルは事前に確保され、ログロールの際に縮小されます。 通常はこの値を変更すべきではありません。
segment.ms
| デフォルト | 7 days |
| サーバデフォルトプロパティ | log.roll.hours |
セグメントファイルが古いデータの削除、またはコンパクション条件を満たしていない場合でも、 この期間が過ぎると強制的に新たなセグメントファイルが作成されます。
segment.jitter.ms
| デフォルト | 0 |
| サーバデフォルトプロパティ | log.roll.jitter.{ms,hours} |
logRollTimeMillis から減じられる最大ジッタです。
3.2 Consumer Configs
The essential consumer configurations are the following:
group.idzookeeper.connect
More details about consumer configuration can be found in the scala class kafka.consumer.ConsumerConfig.
group.id
| デフォルト |
A string that uniquely identifies the group of consumer processes to which this consumer belongs. By setting the same group id multiple processes indicate that they are all part of the same consumer group.
zookeeper.connect
| デフォルト |
Specifies the ZooKeeper connection string in the form hostname:port where host and port are the host and port of a ZooKeeper server. To allow connecting through other ZooKeeper nodes when that ZooKeeper machine is down you can also specify multiple hosts in the form hostname1:port1,hostname2:port2,hostname3:port3. The server may also have a ZooKeeper chroot path as part of it's ZooKeeper connection string which puts its data under some path in the global ZooKeeper namespace. If so the consumer should use the same chroot path in its connection string. For example to give a chroot path of /chroot/path you would give the connection string as hostname1:port1,hostname2:port2,hostname3:port3/chroot/path.
consumer.id
| デフォルト | null |
Generated automatically if not set.
socket.timeout.ms
| デフォルト | 30 * 1000 |
The socket timeout for network requests. The actual timeout set will be max.fetch.wait + socket.timeout.ms.
socket.receive.buffer.bytes
| デフォルト | 64 * 1024 |
The socket receive buffer for network requests
fetch.message.max.bytes
| デフォルト | 1024 * 1024 |
取得リクエスト時に、各トピックパーティションからメッセージを何バイト取得を試みるか、を設定します。 ここで設定されたバイト数分、各トピック毎にメモリに読み込まれるため、 コンシューマのメモリ使用を制御したい場合はこのプロパティを調整することになります。 取得リクエストサイズは少なくとも サーバが許容する最大メッセージサイズ よりも大きくする必要があります。 さもなければ、コンシューマが取得出来ないほど大きなメッセージをプロデューサが送ることが出来てしまいます。
num.consumer.fetchers
| デフォルト | 1 |
The number fetcher threads used to fetch data.
auto.commit.enable
| デフォルト | true |
If true, periodically commit to ZooKeeper the offset of messages already fetched by the consumer. This committed offset will be used when the process fails as the position from which the new consumer will begin.
auto.commit.interval.ms
| デフォルト | 60 * 1000 |
The frequency in ms that the consumer offsets are committed to zookeeper.
queued.max.message.chunks
| デフォルト | 2 |
Max number of message chunks buffered for consumption. Each chunk can be up to fetch.message.max.bytes.
rebalance.max.retries
| デフォルト | 4 |
When a new consumer joins a consumer group the set of consumers attempt to "rebalance" the load to assign partitions to each consumer. If the set of consumers changes while this assignment is taking place the rebalance will fail and retry. This setting controls the maximum number of attempts before giving up.
fetch.min.bytes
| デフォルト | 1 |
The minimum amount of data the server should return for a fetch request. If insufficient data is available the request will wait for that much data to accumulate before answering the request.
fetch.wait.max.ms
| デフォルト | 100 |
The maximum amount of time the server will block before answering the fetch request if there isn't sufficient data to immediately satisfy fetch.min.bytes
rebalance.backoff.ms
| デフォルト | 2000 |
Backoff time between retries during rebalance.
refresh.leader.backoff.ms
| デフォルト | 200 |
Backoff time to wait before trying to determine the leader of a partition that has just lost its leader.
auto.offset.reset
| デフォルト | largest |
What to do when there is no initial offset in ZooKeeper or if an offset is out of range:
- smallest
- automatically reset the offset to the smallest offset
- largest
- automatically reset the offset to the largest offset
- anything else
- throw exception to the consumer
consumer.timeout.ms
| デフォルト | -1 |
Throw a timeout exception to the consumer if no message is available for consumption after the specified interval
exclude.internal.topics
| デフォルト | true |
Whether messages from internal topics (such as offsets) should be exposed to the consumer.
partition.assignment.strategy
| デフォルト | range |
Select a strategy for assigning partitions to consumer streams. Possible values: range, roundrobin.
client.id
| デフォルト | group id value |
The client id is a user-specified string sent in each request to help trace calls. It should logically identify the application making the request.
zookeeper.session.timeout.ms
| デフォルト | 6000 |
ZooKeeper session timeout. If the consumer fails to heartbeat to ZooKeeper for this period of time it is considered dead and a rebalance will occur.
zookeeper.connection.timeout.ms
| デフォルト | 6000 |
The max time that the client waits while establishing a connection to zookeeper.
zookeeper.sync.time.ms
| デフォルト | 2000 |
How far a ZK follower can be behind a ZK leader
offsets.storage
| デフォルト | zookeeper |
Select where offsets should be stored (zookeeper or kafka).
offsets.channel.backoff.ms
| デフォルト | 1000 |
The backoff period when reconnecting the offsets channel or retrying failed offset fetch/commit requests.
offsets.channel.socket.timeout.ms
| デフォルト | 10000 |
Socket timeout when reading responses for offset fetch/commit requests. This timeout is also used for ConsumerMetadata requests that are used to query for the offset manager.
offsets.commit.max.retries
| デフォルト | 5 |
Retry the offset commit up to this many times on failure. This retry count only applies to offset commits during shut-down. It does not apply to commits originating from the auto-commit thread. It also does not apply to attempts to query for the offset coordinator before committing offsets. i.e., if a consumer metadata request fails for any reason, it will be retried and that retry does not count toward this limit.
dual.commit.enabled
| デフォルト | true |
If you are using "kafka" as offsets.storage, you can dual commit offsets to ZooKeeper (in addition to Kafka). This is required during migration from zookeeper-based offset storage to kafka-based offset storage. With respect to any given consumer group, it is safe to turn this off after all instances within that group have been migrated to the new version that commits offsets to the broker (instead of directly to ZooKeeper).
partition.assignment.strategy
| デフォルト | range |
Select between the "range" or "roundrobin" strategy for assigning partitions to consumer streams.
The round-robin partition assignor lays out all the available partitions and all the available consumer threads. It then proceeds to do a round-robin assignment from partition to consumer thread. If the subscriptions of all consumer instances are identical, then the partitions will be uniformly distributed. (i.e., the partition ownership counts will be within a delta of exactly one across all consumer threads.) Round-robin assignment is permitted only if: (a) Every topic has the same number of streams within a consumer instance (b) The set of subscribed topics is identical for every consumer instance within the group.
Range partitioning works on a per-topic basis. For each topic, we lay out the available partitions in numeric order and the consumer threads in lexicographic order. We then divide the number of partitions by the total number of consumer streams (threads) to determine the number of partitions to assign to each consumer. If it does not evenly divide, then the first few consumers will have one extra partition.
3.3 Producer Configs
Essential configuration properties for the producer include:
metadata.broker.listrequest.required.acksproducer.typeserializer.class
More details about producer configuration can be found in the scala class kafka.producer.ProducerConfig.
metadata.broker.list
| Default |
This is for bootstrapping and the producer will only use it for getting metadata (topics, partitions and replicas). The socket connections for sending the actual data will be established based on the broker information returned in the metadata. The format is host1:port1,host2:port2, and the list can be a subset of brokers or a VIP pointing to a subset of brokers.
request.required.acks
| Default | 0 |
This value controls when a produce request is considered completed. Specifically, how many other brokers must have committed the data to their log and acknowledged this to the leader? Typical values are
- 0, which means that the producer never waits for an acknowledgement from the broker (the same behavior as 0.7). This option provides the lowest latency but the weakest durability guarantees (some data will be lost when a server fails).
- 1, which means that the producer gets an acknowledgement after the leader replica has received the data. This option provides better durability as the client waits until the server acknowledges the request as successful (only messages that were written to the now-dead leader but not yet replicated will be lost).
- -1, The producer gets an acknowledgement after all in-sync replicas have received the data. This option provides the greatest level of durability. However, it does not completely eliminate the risk of message loss because the number of in sync replicas may, in rare cases, shrink to 1. If you want to ensure that some minimum number of replicas (typically a majority) receive a write, then you must set the topic-level min.insync.replicas setting. Please read the Replication section of the design documentation for a more in-depth discussion.
request.timeout.ms
| Default | 10000 |
The amount of time the broker will wait trying to meet the request.required.acks requirement before sending back an error to the client.
producer.type
| Default | sync |
This parameter specifies whether the messages are sent asynchronously in a background thread. Valid values are (1) async for asynchronous send and (2) sync for synchronous send. By setting the producer to async we allow batching together of requests (which is great for throughput) but open the possibility of a failure of the client machine dropping unsent data.
serializer.class
| Default | kafka.serializer.DefaultEncoder |
The serializer class for messages. The default encoder takes a byte[] and returns the same byte[].
key.serializer.class
| Default |
The serializer class for keys (defaults to the same as for messages if nothing is given).
partitioner.class
| Default | kafka.producer.DefaultPartitioner |
The partitioner class for partitioning messages amongst sub-topics. The default partitioner is based on the hash of the key.
compression.codec
| Default | none |
This parameter allows you to specify the compression codec for all data generated by this producer. Valid values are "none", "gzip" and "snappy".
compressed.topics
| Default | null |
This parameter allows you to set whether compression should be turned on for particular topics. If the compression codec is anything other than NoCompressionCodec, enable compression only for specified topics if any. If the list of compressed topics is empty, then enable the specified compression codec for all topics. If the compression codec is NoCompressionCodec, compression is disabled for all topics
message.send.max.retries
| Default | 3 |
This property will cause the producer to automatically retry a failed send request. This property specifies the number of retries when such failures occur. Note that setting a non-zero value here can lead to duplicates in the case of network errors that cause a message to be sent but the acknowledgement to be lost.
retry.backoff.ms
| Default | 100 |
Before each retry, the producer refreshes the metadata of relevant topics to see if a new leader has been elected. Since leader election takes a bit of time, this property specifies the amount of time that the producer waits before refreshing the metadata.
topic.metadata.refresh.interval.ms
| Default | 600 * 1000 |
The producer generally refreshes the topic metadata from brokers when there is a failure (partition missing, leader not available…). It will also poll regularly (default: every 10min so 600000ms). If you set this to a negative value, metadata will only get refreshed on failure. If you set this to zero, the metadata will get refreshed after each message sent (not recommended). Important note: the refresh happen only AFTER the message is sent, so if the producer never sends a message the metadata is never refreshed
queue.buffering.max.ms
| Default | 5000 |
Maximum time to buffer data when using async mode. For example a setting of 100 will try to batch together 100ms of messages to send at once. This will improve throughput but adds message delivery latency due to the buffering.
queue.buffering.max.messages
| Default | 10000 |
The maximum number of unsent messages that can be queued up the producer when using async mode before either the producer must be blocked or data must be dropped.
queue.enqueue.timeout.ms
| Default | -1 |
The amount of time to block before dropping messages when running in async mode and the buffer has reached queue.buffering.max.messages. If set to 0 events will be enqueued immediately or dropped if the queue is full (the producer send call will never block). If set to -1 the producer will block indefinitely and never willingly drop a send.
batch.num.messages
| Default | 200 |
The number of messages to send in one batch when using async mode. The producer will wait until either this number of messages are ready to send or queue.buffer.max.ms is reached.
send.buffer.bytes
| Default | 100 * 1024 |
Socket write buffer size
client.id
| Default | "" |
The client id is a user-specified string sent in each request to help trace calls. It should logically identify the application making the request.
3.4 New Producer Configs
We are working on a replacement for our existing producer. The code is available in trunk now and can be considered beta quality. Below is the configuration for the new producer. 13
bootstrap.servers
| Type | list |
| Default | |
| Importance | high |
A list of host/port pairs to use for establishing the initial connection to the Kafka cluster. Data will be load balanced over all servers irrespective of which servers are specified here for bootstrapping—this list only impacts the initial hosts used to discover the full set of servers. This list should be in the form host1:port1,host2:port2,…. Since these servers are just used for the initial connection to discover the full cluster membership (which may change dynamically), this list need not contain the full set of servers (you may want more than one, though, in case a server is down). If no server in this list is available sending data will fail until on becomes available.
acks
| Type | string |
| Default | 1 |
| Importance | high |
The number of acknowledgments the producer requires the leader to have received before considering a request complete. This controls the durability of records that are sent. The following settings are common:
acks=0If set to zero then the producer will not wait for any acknowledgment from the server at all. The record will be immediately added to the socket buffer and considered sent. No guarantee can be made that the server has received the record in this case, and theretriesconfiguration will not take effect (as the client won't generally know of any failures). The offset given back for each record will always be set to -1.acks=1This will mean the leader will write the record to its local log but will respond without awaiting full acknowledgement from all followers. In this case should the leader fail immediately after acknowledging the record but before the followers have replicated it then the record will be lost.acks=allThis means the leader will wait for the full set of in-sync replicas to acknowledge the record. This guarantees that the record will not be lost as long as at least one in-sync replica remains alive. This is the strongest available guarantee.- Other settings such as
acks=2are also possible, and will require the given number of acknowledgements but this is generally less useful.
buffer.memory
| Type | long |
| Default | 33554432 |
| Importance | high |
The total bytes of memory the producer can use to buffer records waiting to be sent to the server. If records are sent faster than they can be delivered to the server the producer will either block or throw an exception based on the preference specified by block.on.buffer.full.
This setting should correspond roughly to the total memory the producer will use, but is not a hard bound since not all memory the producer uses is used for buffering. Some additional memory will be used for compression (if compression is enabled) as well as for maintaining in-flight requests.
compression.type
| Type | string |
| Default | none |
| Importance | high |
The compression type for all data generated by the producer. The default is none (i.e. no compression). Valid values are none, gzip, or snappy. Compression is of full batches of data, so the efficacy of batching will also impact the compression ratio (more batching means better compression).
retries
| Type | int |
| Default | 0 |
| Importance | high |
Setting a value greater than zero will cause the client to resend any record whose send fails with a potentially transient error. Note that this retry is no different than if the client resent the record upon receiving the error. Allowing retries will potentially change the ordering of records because if two records are sent to a single partition, and the first fails and is retried but the second succeeds, then the second record may appear first.
batch.size
| Type | int |
| Default | 16384 |
| Importance | medium |
The producer will attempt to batch records together into fewer requests whenever multiple records are being sent to the same partition. This helps performance on both the client and the server. This configuration controls the default batch size in bytes.
No attempt will be made to batch records larger than this size.
Requests sent to brokers will contain multiple batches, one for each partition with data available to be sent.
A small batch size will make batching less common and may reduce throughput (a batch size of zero will disable batching entirely). A very large batch size may use memory a bit more wastefully as we will always allocate a buffer of the specified batch size in anticipation of additional records.
client.id
| Type | string |
| Default | |
| Importance | medium |
The id string to pass to the server when making requests. The purpose of this is to be able to track the source of requests beyond just ip/port by allowing a logical application name to be included with the request. The application can set any string it wants as this has no functional purpose other than in logging and metrics.
linger.ms
| Type | long |
| Default | 0 |
| Importance | medium |
The producer groups together any records that arrive in between request transmissions into a single batched request. Normally this occurs only under load when records arrive faster than they can be sent out. However in some circumstances the client may want to reduce the number of requests even under moderate load. This setting accomplishes this by adding a small amount of artificial delay—that is, rather than immediately sending out a record the producer will wait for up to the given delay to allow other records to be sent so that the sends can be batched together. This can be thought of as analogous to Nagle's algorithm in TCP. This setting gives the upper bound on the delay for batching: once we get batch.size worth of records for a partition it will be sent immediately regardless of this setting, however if we have fewer than this many bytes accumulated for this partition we will 'linger' for the specified time waiting for more records to show up. This setting defaults to 0 (i.e. no delay). Setting linger.ms=5, for example, would have the effect of reducing the number of requests sent but would add up to 5ms of latency to records sent in the absense of load.
max.request.size
| Type | int |
| Default | 1048576 |
| Importance | medium |
The maximum size of a request. This is also effectively a cap on the maximum record size. Note that the server has its own cap on record size which may be different from this. This setting will limit the number of record batches the producer will send in a single request to avoid sending huge requests.
receive.buffer.bytes
| Type | int |
| Default | 32768 |
| Importance | medium |
The size of the TCP receive buffer to use when reading data
send.buffer.bytes
| Type | int |
| Default | 131072 |
| Importance | medium |
The size of the TCP send buffer to use when sending data
timeout.ms
| Type | int |
| Default | 30000 |
| Importance | medium |
The configuration controls the maximum amount of time the server will wait for acknowledgments from followers to meet the acknowledgment requirements the producer has specified with the acks configuration. If the requested number of acknowledgments are not met when the timeout elapses an error will be returned. This timeout is measured on the server side and does not include the network latency of the request.
block.on.buffer.full
| Type | boolean |
| Default | true |
| Importance | low |
When our memory buffer is exhausted we must either stop accepting new records (block) or throw errors. By default this setting is true and we block, however in some scenarios blocking is not desirable and it is better to immediately give an error. Setting this to false will accomplish that: the producer will throw a BufferExhaustedException if a recrord is sent and the buffer space is full.
metadata.fetch.timeout.ms
| Type | long |
| Default | 60000 |
| Importance | low |
The first time data is sent to a topic we must fetch metadata about that topic to know which servers host the topic's partitions. This configuration controls the maximum amount of time we will block waiting for the metadata fetch to succeed before throwing an exception back to the client.
metadata.max.age.ms
| Type | long |
| Default | 300000 |
| Importance | low |
The period of time in milliseconds after which we force a refresh of metadata even if we haven't seen any partition leadership changes to proactively discover any new brokers or partitions.
metric.reporters
| Type | list |
| Default | [] |
| Importance | low |
A list of classes to use as metrics reporters. Implementing the MetricReporter interface allows plugging in classes that will be notified of new metric creation. The JmxReporter is always included to register JMX statistics.
metrics.num.samples
| Type | int |
| Default | 2 |
| Importance | low |
The number of samples maintained to compute metrics.
metrics.sample.window.ms
| Type | long |
| Default | 30000 |
| Importance | low |
The metrics system maintains a configurable number of samples over a fixed window size. This configuration controls the size of the window. For example we might maintain two samples each measured over a 30 second period. When a window expires we erase and overwrite the oldest window.
reconnect.backoff.ms
| Type | long |
| Default | 10 |
| Importance | low |
The amount of time to wait before attempting to reconnect to a given host when a connection fails. This avoids a scenario where the client repeatedly attempts to connect to a host in a tight loop.
retry.backoff.ms
| Type | long |
| Default | 100 |
| Importance | low |
The amount of time to wait before attempting to retry a failed produce request to a given topic partition. This avoids repeated sending-and-failing in a tight loop.
4 設計
4.1 動機
We designed Kafka to be able to act as a unified platform for handling all the real-time data feeds a large company might have. To do this we had to think through a fairly broad set of use cases.
It would have to have high-throughput to support high volume event streams such as real-time log aggregation.
It would need to deal gracefully with large data backlogs to be able to support periodic data loads from offline systems.
It also meant the system would have to handle low-latency delivery to handle more traditional messaging use-cases.
We wanted to support partitioned, distributed, real-time processing of these feeds to create new, derived feeds. This motivated our partitioning and consumer model.
Finally in cases where the stream is fed into other data systems for serving we new the system would have to be able to guarantee fault-tolerance in the presence of machine failures.
Supporting these uses led use to a design with a number of unique elements, more akin to a database log then a traditional messaging system. We will outline some elements of the design in the following sections.
4.2 永続化
Don't fear the filesystem!
Kafka relies heavily on the filesystem for storing and caching messages. There is a general perception that "disks are slow" which makes people skeptical that a persistent structure can offer competitive performance. In fact disks are both much slower and much faster than people expect depending on how they are used; and a properly designed disk structure can often be as fast as the network.
The key fact about disk performance is that the throughput of hard drives has been diverging from the latency of a disk seek for the last decade. As a result the performance of linear writes on a JBOD configuration with six 7200rpm SATA RAID-5 array is about 600MB/sec but the performance of random writes is only about 100k/sec—a difference of over 6000X. These linear reads and writes are the most predictable of all usage patterns, and are heavily optimized by the operating system. A modern operating system provides read-ahead and write-behind techniques that prefetch data in large block multiples and group smaller logical writes into large physical writes. A further discussion of this issue can be found in this ACM Queue article; they actually find that sequential disk access can in some cases be faster than random memory access!
{kind=link}
To compensate for this performance divergence modern operating systems have become increasingly aggressive in their use of main memory for disk caching. A modern OS will happily divert all free memory to disk caching with little performance penalty when the memory is reclaimed. All disk reads and writes will go through this unified cache. This feature cannot easily be turned off without using direct I/O, so even if a process maintains an in-process cache of the data, this data will likely be duplicated in OS pagecache, effectively storing everything twice.
Furthermore we are building on top of the JVM, and anyone who has spent any time with Java memory usage knows two things:
- The memory overhead of objects is very high, often doubling the size of the data stored (or worse).
- Java garbage collection becomes increasingly fiddly and slow as the in-heap data increases.
As a result of these factors using the filesystem and relying on pagecache is superior to maintaining an in-memory cache or other structure—we at least double the available cache by having automatic access to all free memory, and likely double again by storing a compact byte structure rather than individual objects. Doing so will result in a cache of up to 28-30GB on a 32GB machine without GC penalties. Furthermore this cache will stay warm even if the service is restarted, whereas the in-process cache will need to be rebuilt in memory (which for a 10GB cache may take 10 minutes) or else it will need to start with a completely cold cache (which likely means terrible initial performance). This also greatly simplifies the code as all logic for maintaining coherency between the cache and filesystem is now in the OS, which tends to do so more efficiently and more correctly than one-off in-process attempts. If your disk usage favors linear reads then read-ahead is effectively pre-populating this cache with useful data on each disk read.
This suggests a design which is very simple: rather than maintain as much as possible in-memory and flush it all out to the filesystem in a panic when we run out of space, we invert that. All data is immediately written to a persistent log on the filesystem without necessarily flushing to disk. In effect this just means that it is transferred into the kernel's pagecache.
This style of pagecache-centric design is described in an article on the design of Varnish here (along with a healthy dose of arrogance).
Constant Time Suffices
The persistent data structure used in messaging systems are often a per-consumer queue with an associated BTree or other general-purpose random access data structures to maintain metadata about messages. BTrees are the most versatile data structure available, and make it possible to support a wide variety of transactional and non-transactional semantics in the messaging system. They do come with a fairly high cost, though: Btree operations are O(log N). Normally O(log N) is considered essentially equivalent to constant time, but this is not true for disk operations. Disk seeks come at 10 ms a pop, and each disk can do only one seek at a time so parallelism is limited. Hence even a handful of disk seeks leads to very high overhead. Since storage systems mix very fast cached operations with very slow physical disk operations, the observed performance of tree structures is often superlinear as data increases with fixed cache–i.e. doubling your data makes things much worse then twice as slow.
Intuitively a persistent queue could be built on simple reads and appends to files as is commonly the case with logging solutions. This structure has the advantage that all operations are O(1) and reads do not block writes or each other. This has obvious performance advantages since the performance is completely decoupled from the data size—one server can now take full advantage of a number of cheap, low-rotational speed 1+TB SATA drives. Though they have poor seek performance, these drives have acceptable performance for large reads and writes and come at 1/3 the price and 3x the capacity.
Having access to virtually unlimited disk space without any performance penalty means that we can provide some features not usually found in a messaging system. For example, in Kafka, instead of attempting to deleting messages as soon as they are consumed, we can retain messages for a relative long period (say a week). This leads to a great deal of flexibility for consumers, as we will describe.
4.3 Efficiency
We have put significant effort into efficiency. One of our primary use cases is handling web activity data, which is very high volume: each page view may generate dozens of writes. Furthermore we assume each message published is read by at least one consumer (often many), hence we strive to make consumption as cheap as possible.
We have also found, from experience building and running a number of similar systems, that efficiency is a key to effective multi-tenant operations. If the downstream infrastructure service can easily become a bottleneck due to a small bump in usage by the application, such small changes will often create problems. By being very fast we help ensure that the application will tip-over under load before the infrastructure. This is particularly important when trying to run a centralized service that supports dozens or hundreds of applications on a centralized cluster as changes in usage patterns are a near-daily occurrence.
We discussed disk efficiency in the previous section. Once poor disk access patterns have been eliminated, there are two common causes of inefficiency in this type of system: too many small I/O operations, and excessive byte copying.
The small I/O problem happens both between the client and the server and in the server's own persistent operations.
To avoid this, our protocol is built around a "message set" abstraction that naturally groups messages together. This allows network requests to group messages together and amortize the overhead of the network roundtrip rather than sending a single message at a time. The server in turn appends chunks of messages to its log in one go, and the consumer fetches large linear chunks at a time.
This simple optimization produces orders of magnitude speed up. Batching leads to larger network packets, larger sequential disk operations, contiguous memory blocks, and so on, all of which allows Kafka to turn a bursty stream of random message writes into linear writes that flow to the consumers.
The other inefficiency is in byte copying. At low message rates this is not an issue, but under load the impact is significant. To avoid this we employ a standardized binary message format that is shared by the producer, the broker, and the consumer (so data chunks can be transferred without modification between them).
The message log maintained by the broker is itself just a directory of files, each populated by a sequence of message sets that have been written to disk in the same format used by the producer and consumer. Maintaining this common format allows optimization of the most important operation: network transfer of persistent log chunks. Modern unix operating systems offer a highly optimized code path for transferring data out of pagecache to a socket; in Linux this is done with the sendfile sendfile system call.
To understand the impact of sendfile, it is important to understand the common data path for transfer of data from file to socket:
- The operating system reads data from the disk into pagecache in kernel space
- The application reads the data from kernel space into a user-space buffer
- The application writes the data back into kernel space into a socket buffer
- The operating system copies the data from the socket buffer to the NIC buffer where it is sent over the network
This is clearly inefficient, there are four copies and two system calls. Using sendfile, this re-copying is avoided by allowing the OS to send the data from pagecache to the network directly. So in this optimized path, only the final copy to the NIC buffer is needed.
We expect a common use case to be multiple consumers on a topic. Using the zero-copy optimization above, data is copied into pagecache exactly once and reused on each consumption instead of being stored in memory and copied out to kernel space every time it is read. This allows messages to be consumed at a rate that approaches the limit of the network connection.
This combination of pagecache and sendfile means that on a Kafka cluster where the consumers are mostly caught up you will see no read activity on the disks whatsoever as they will be serving data entirely from cache.
For more background on the sendfile and zero-copy support in Java, see this article.
End-to-end Batch Compression
In some cases the bottleneck is actually not CPU or disk but network bandwidth. This is particularly true for a data pipeline that needs to send messages between data centers over a wide-area network. Of course the user can always compress its messages one at a time without any support needed from Kafka, but this can lead to very poor compression ratios as much of the redundancy is due to repetition between messages of the same type (e.g. field names in JSON or user agents in web logs or common string values). Efficient compression requires compressing multiple messages together rather than compressing each message individually.
Kafka supports this by allowing recursive message sets. A batch of messages can be clumped together compressed and sent to the server in this form. This batch of messages will be written in compressed form and will remain compressed in the log and will only be decompressed by the consumer.
Kafka supports GZIP and Snappy compression protocols. More details on compression can be found here.
4.4 The Producer
Load balancing
The producer sends data directly to the broker that is the leader for the partition without any intervening routing tier. To help the producer do this all Kafka nodes can answer a request for metadata about which servers are alive and where the leaders for the partitions of a topic are at any given time to allow the producer to appropriate direct its requests.
The client controls which partition it publishes messages to. This can be done at random, implementing a kind of random load balancing, or it can be done by some semantic partitioning function. We expose the interface for semantic partitioning by allowing the user to specify a key to partition by and using this to hash to a partition (there is also an option to override the partition function if need be). For example if the key chosen was a user id then all data for a given user would be sent to the same partition. This in turn will allow consumers to make locality assumptions about their consumption. This style of partitioning is explicitly designed to allow locality-sensitive processing in consumers.
Asynchronous send
Batching is one of the big drivers of efficiency, and to enable batching the Kafka producer will attempt to accumulate data in memory and to send out larger batches in a single request. The batching can be configured to accumulate no more than a fixed number of messages and to wait no longer than some fixed latency bound (say 64k or 10 ms). This allows the accumulation of more bytes to send, and few larger I/O operations on the servers. This buffering is configurable and gives a mechanism to trade off a small amount of additional latency for better throughput.
Details on configuration and api for the producer can be found elsewhere in the documentation.
4.5 The Consumer
The Kafka consumer works by issuing "fetch" requests to the brokers leading the partitions it wants to consume. The consumer specifies its offset in the log with each request and receives back a chunk of log beginning from that position. The consumer thus has significant control over this position and can rewind it to re-consume data if need be.
Push vs. pull
An initial question we considered is whether consumers should pull data from brokers or brokers should push data to the consumer. In this respect Kafka follows a more traditional design, shared by most messaging systems, where data is pushed to the broker from the producer and pulled from the broker by the consumer. Some logging-centric systems, such as Scribe and Apache Flume follow a very different push based path where data is pushed downstream. There are pros and cons to both approaches. However a push-based system has difficulty dealing with diverse consumers as the broker controls the rate at which data is transferred. The goal is generally for the consumer to be able to consume at the maximum possible rate; unfortunately in a push system this means the consumer tends to be overwhelmed when its rate of consumption falls below the rate of production (a denial of service attack, in essence). A pull-based system has the nicer property that the consumer simply falls behind and catches up when it can. This can be mitigated with some kind of backoff protocol by which the consumer can indicate it is overwhelmed, but getting the rate of transfer to fully utilize (but never over-utilize) the consumer is trickier than it seems. Previous attempts at building systems in this fashion led us to go with a more traditional pull model.
Another advantage of a pull-based system is that it lends itself to aggressive batching of data sent to the consumer. A push-based system must choose to either send a request immediately or accumulate more data and then send it later without knowledge of whether the downstream consumer will be able to immediately process it. If tuned for low latency this will result in sending a single message at a time only for the transfer to end up being buffered anyway, which is wasteful. A pull-based design fixes this as the consumer always pulls all available messages after its current position in the log (or up to some configurable max size). So one gets optimal batching without introducing unnecessary latency.
The deficiency of a naive pull-based system is that if the broker has no data the consumer may end up polling in a tight loop, effectively busy-waiting for data to arrive. To avoid this we have parameters in our pull request that allow the consumer request to block in a "long poll" waiting until data arrives (and optionally waiting until a given number of bytes is available to ensure large transfer sizes).
You could imagine other possible designs which would be only pull, end-to-end. The producer would locally write to a local log, and brokers would pull from that with consumers pulling from them. A similar type of "store-and-forward" producer is often proposed. This is intriguing but we felt not very suitable for our target use cases which have thousands of producers. Our experience running persistent data systems at scale led us to feel that involving thousands of disks in the system across many applications would not actually make things more reliable and would be a nightmare to operate. And in practice we have found that we can run a pipeline with strong SLAs at large scale without a need for producer persistence.
Consumer Position
Keeping track of what has been consumed, is, surprisingly, one of the key performance points of a messaging system.
Most messaging systems keep metadata about what messages have been consumed on the broker. That is, as a message is handed out to a consumer, the broker either records that fact locally immediately or it may wait for acknowledgement from the consumer. This is a fairly intuitive choice, and indeed for a single machine server it is not clear where else this state could go. Since the data structure used for storage in many messaging systems scale poorly, this is also a pragmatic choice–since the broker knows what is consumed it can immediately delete it, keeping the data size small.
What is perhaps not obvious, is that getting the broker and consumer to come into agreement about what has been consumed is not a trivial problem. If the broker records a message as consumed immediately every time it is handed out over the network, then if the consumer fails to process the message (say because it crashes or the request times out or whatever) that message will be lost. To solve this problem, many messaging systems add an acknowledgement feature which means that messages are only marked as sent not consumed when they are sent; the broker waits for a specific acknowledgement from the consumer to record the message as consumed. This strategy fixes the problem of losing messages, but creates new problems. First of all, if the consumer processes the message but fails before it can send an acknowledgement then the message will be consumed twice. The second problem is around performance, now the broker must keep multiple states about every single message (first to lock it so it is not given out a second time, and then to mark it as permanently consumed so that it can be removed). Tricky problems must be dealt with, like what to do with messages that are sent but never acknowledged.
Kafka handles this differently. Our topic is divided into a set of totally ordered partitions, each of which is consumed by one consumer at any given time. This means that the position of consumer in each partition is just a single integer, the offset of the next message to consume. This makes the state about what has been consumed very small, just one number for each partition. This state can be periodically checkpointed. This makes the equivalent of message acknowledgements very cheap.
There is a side benefit of this decision. A consumer can deliberately rewind back to an old offset and re-consume data. This violates the common contract of a queue, but turns out to be an essential feature for many consumers. For example, if the consumer code has a bug and is discovered after some messages are consumed, the consumer can re-consume those messages once the bug is fixed.
Offline Data Load
Scalable persistence allows for the possibility of consumers that only periodically consume such as batch data loads that periodically bulk-load data into an offline system such as Hadoop or a relational data warehouse.
In the case of Hadoop we parallelize the data load by splitting the load over individual map tasks, one for each node/topic/partition combination, allowing full parallelism in the loading. Hadoop provides the task management, and tasks which fail can restart without danger of duplicate data—they simply restart from their original position.
4.6 Message Delivery Semantics
Now that we understand a little about how producers and consumers work, let's discuss the semantic guarantees Kafka provides between producer and consumer. Clearly there are multiple possible message delivery guarantees that could be provided:
- At most once — Messages may be lost but are never redelivered.
- At least once — Messages are never lost but may be redelivered.
- Exactly once — this is what people actually want, each message is delivered once and only once.
It's worth noting that this breaks down into two problems: the durability guarantees for publishing a message and the guarantees when consuming a message.
Many systems claim to provide "exactly once" delivery semantics, but it is important to read the fine print, most of these claims are misleading (i.e. they don't translate to the case where consumers or producers can fail, or cases where there are multiple consumer processes, or cases where data written to disk can be lost).
Kafka's semantics are straight-forward. When publishing a message we have a notion of the message being "committed" to the log. Once a published message is committed it will not be lost as long as one broker that replicates the partition to which this message was written remains "alive". The definition of alive as well as a description of which types of failures we attempt to handle will be described in more detail in the next section. For now let's assume a perfect, lossless broker and try to understand the guarantees to the producer and consumer. If a producer attempts to publish a message and experiences a network error it cannot be sure if this error happened before or after the message was committed. This is similar to the semantics of inserting into a database table with an autogenerated key.
These are not the strongest possible semantics for publishers. Although we cannot be sure of what happened in the case of a network error, it is possible to allow the producer to generate a sort of "primary key" that makes retrying the produce request idempotent. This feature is not trivial for a replicated system because of course it must work even (or especially) in the case of a server failure. With this feature it would suffice for the producer to retry until it receives acknowledgement of a successfully committed message at which point we would guarantee the message had been published exactly once. We hope to add this in a future Kafka version.
Not all use cases require such strong guarantees. For uses which are latency sensitive we allow the producer to specify the durability level it desires. If the producer specifies that it wants to wait on the message being committed this can take on the order of 10 ms. However the producer can also specify that it wants to perform the send completely asynchronously or that it wants to wait only until the leader (but not necessarily the followers) have the message.
Now let's describe the semantics from the point-of-view of the consumer. All replicas have the exact same log with the same offsets. The consumer controls its position in this log. If the consumer never crashed it could just store this position in memory, but if the consumer fails and we want this topic partition to be taken over by another process the new process will need to choose an appropriate position from which to start processing. Let's say the consumer reads some messages – it has several options for processing the messages and updating its position.
- It can read the messages, then save its position in the log, and finally process the messages. In this case there is a possibility that the consumer process crashes after saving its position but before saving the output of its message processing. In this case the process that took over processing would start at the saved position even though a few messages prior to that position had not been processed. This corresponds to "at-most-once" semantics as in the case of a consumer failure messages may not be processed.
- It can read the messages, process the messages, and finally save its position. In this case there is a possibility that the consumer process crashes after processing messages but before saving its position. In this case when the new process takes over the first few messages it receives will already have been processed. This corresponds to the "at-least-once" semantics in the case of consumer failure. In many cases messages have a primary key and so the updates are idempotent (receiving the same message twice just overwrites a record with another copy of itself).
- So what about exactly once semantics (i.e. the thing you actually want)? The limitation here is not actually a feature of the messaging system but rather the need to co-ordinate the consumer's position with what is actually stored as output. The classic way of achieving this would be to introduce a two-phase commit between the storage for the consumer position and the storage of the consumers output. But this can be handled more simply and generally by simply letting the consumer store its offset in the same place as its output. This is better because many of the output systems a consumer might want to write to will not support a two-phase commit. As an example of this, our Hadoop ETL that populates data in HDFS stores its offsets in HDFS with the data it reads so that it is guaranteed that either data and offsets are both updated or neither is. We follow similar patterns for many other data systems which require these stronger semantics and for which the messages do not have a primary key to allow for deduplication.
So effectively Kafka guarantees at-least-once delivery by default and allows the user to implement at most once delivery by disabling retries on the producer and committing its offset prior to processing a batch of messages. Exactly-once delivery requires co-operation with the destination storage system but Kafka provides the offset which makes implementing this straight-forward.
4.7 レプリケーション
▶ show original text
Replication
Kafka replicates the log for each topic's partitions across a configurable number of servers (you can set this replication factor on a topic-by-topic basis). This allows automatic failover to these replicas when a server in the cluster fails so messages remain available in the presence of failures.
Kafkaは各トピックのパーティションログを、設定に応じた数のサーバに複製します (レプリケーションファクタはトピック毎に設定することが出来ます)。 これによりクラスタ内のサーバに障害が発生しても、この複製を利用して自動フェイルオーバすることが可能になり、 障害発生中でもメッセージが利用可能になります。
▶ show original text
Other messaging systems provide some replication-related features, but, in our (totally biased) opinion, this appears to be a tacked-on thing, not heavily used, and with large downsides: slaves are inactive, throughput is heavily impacted, it requires fiddly manual configuration, etc. Kafka is meant to be used with replication by default— in fact we implement un-replicated topics as replicated topics where the replication factor is one.
他のメッセージングシステムでもレプリケーションのような機能を提供する場合もありますが、 追加機能の一種であり、多用されているとは言えず、 また、スレーブが非活性であったり、スループットに多大な影響があったり、面倒な手動設定が必要だったりなど 大きなマイナス面が伴う場合があるように思われます(完全に偏った意見ですが)。 Kafkaはデフォルトでレプリケーションと共に使用されます—— 複製を持たないトピックは実はレプリケーションファクタが1の複製を持つトピックとして実装されているのです。
▶ show original text
The unit of replication is the topic partition. Under non-failure conditions, each partition in Kafka has a single leader and zero or more followers. The total number of replicas including the leader constitute the replication factor. All reads and writes go to the leader of the partition. Typically, there are many more partitions than brokers and the leaders are evenly distributed among brokers. The logs on the followers are identical to the leader's log—all have the same offsets and messages in the same order (though, of course, at any given time the leader may have a few as-yet unreplicated messages at the end of its log).
レプリケーションの単位はトピックのパーティションです。 正常時はKafkaの各パーティションには単一のリーダ、及び0以上のフォロワが存在します。 リーダのものを含む複製の合計数が、すなわちレプリケーションファクタです。 全ての読み書きはリーダのパーティションを参照します。 ブローカの数よりもずっと多くのパーティションがあり、 リーダがブローカ間で均等に分散している、というのが典型的なシナリオでしょう。 フォロワにあるログはリーダのログと全く同一です—— 全て同じオフセットとメッセージを、同じ順番で記録しています (但し、もちろん、未複製のメッセージがリーダのログ末尾に多少存在するタイミングは存在します)。
▶ show original text
Followers consume messages from the leader just as a normal Kafka consumer would and apply them to their own log. Having the followers pull from the leader has the nice property of allowing the follower to naturally batch together log entries they are applying to their log.
フォロワは通常のKafkaコンシューマと同様にリーダからメッセージをコンシュームし、自身のログに反映します。 このようにリーダからフォロワがpullするという仕組みは、 フォロワが自身のログに反映するログエントリをひとまとめにするということが自然に行えるようにするのに都合が良いのです。
▶ show original text
As with most distributed systems automatically handling failures requires having a precise definition of what it means for a node to be "alive". For Kafka node liveness has two conditions
自動で障害をハンドリングする分散システムでは、大抵、 ノードが「生きている」というのが何を意味するのかを正確に定義することが必要になります。 Kafkaでは生存判定を以下の2つの条件で行ないます。
▶ show original text
- A node must be able to maintain its session with ZooKeeper (via ZooKeeper's heartbeat mechanism)
- If it is a slave it must replicate the writes happening on the leader and not fall "too far" behind
- そのノードが(ZooKeeperのハートビート機構を通じて)ZooKeeperとのセッションを保持すること
- そのノードがスレーブの場合、リーダに対して行われた書き込みが複製され、かつ、「かけ離れ」てしまわないこと
▶ show original text
We refer to nodes satisfying these two conditions as being "in sync" to avoid the vagueness of "alive" or "failed". The leader keeps track of the set of "in sync" nodes. If a follower dies, gets stuck, or falls behind, the leader will remove it from the list of in sync replicas. The definition of, how far behind is too far, is controlled by the replica.lag.max.messages configuration and the definition of a stuck replica is controlled by the replica.lag.time.max.ms configuration.
「alive」や「failed」といった漠然とした表現を避ける為、
この二つの条件を満たすノードを「in sync」と呼ぶことにします。
フォロワが死んだ、詰まった、かけ離れてしまったとき、
リーダはin syncな複製のリスト(ISR)から対象フォロワを除外します。
「かけ離れる」というのがどのくらいなのか、の定義は replica.lag.max.messages で制御することが出来ます。
また、複製が「詰まった」の定義は replica.lag.time.max.ms で制御出来ます。
▶ show original text
In distributed systems terminology we only attempt to handle a "fail/recover" model of failures where nodes suddenly cease working and then later recover (perhaps without knowing that they have died). Kafka does not handle so-called "Byzantine" failures in which nodes produce arbitrary or malicious responses (perhaps due to bugs or foul play).
分散システムの用語で言うと、Kafkaが対応を想定しているのは障害の「fail/recover」モデル、 つまり、ノードが突然稼動停止してしまい、しばらくすると(おそらく自分が死んだことにも気付かずに)復旧する、というモデルです。 「Byzantine」と呼ばれる障害、つまりノードが(バグや不正な行為によって)任意の、あるいは悪意のあるレスポンスを送出するようなものは、 Kafkaでは取り扱いません。
▶ show original text
A message is considered "committed" when all in sync replicas for that partition have applied it to their log. Only committed messages are ever given out to the consumer. This means that the consumer need not worry about potentially seeing a message that could be lost if the leader fails. Producers, on the other hand, have the option of either waiting for the message to be committed or not, depending on their preference for tradeoff between latency and durability. This preference is controlled by the request.required.acks setting that the producer uses.
あるメッセージが「コミット済み」とは、
そのパーティションの全てのin syncな複製が自身のログにメッセージを反映した状態を言います。
コンシューマにはコミット済みのメッセージしか渡されません。
つまり、コンシューマはリーダに障害が発生したときにメッセージがロストするということを考慮する必要は無いということです。
他方、プロデューサは、レイテンシと堅牢性のトレードオフの下、
メッセージのコミットを待つかどうか、という選択をすることが可能です。
これはプロデューサの request.required.acks 14 を設定することで制御出来ます。
▶ show original text
The guarantee that Kafka offers is that a committed message will not be lost, as long as there is at least one in sync replica alive, at all times.
最低1つのin syncな複製が生存している限りは常に、 コミット済みメッセージは失われないことをKafkaは保証します。
▶ show original text
Kafka will remain available in the presence of node failures after a short fail-over period, but may not remain available in the presence of network partitions.
Kafkaはノードの障害発生時には短いフェイルオーバ期間の後にサービス継続可能ですが、 ネットワーク分断が発生した際には不可能です。
Replicated Logs: Quorums, ISRs, and State Machines (Oh my!)
At its heart a Kafka partition is a replicated log. The replicated log is one of the most basic primitives in distributed data systems, and there are many approaches for implementing one. A replicated log can be used by other systems as a primitive for implementing other distributed systems in the state-machine style.
A replicated log models the process of coming into consensus on the order of a series of values (generally numbering the log entries 0, 1, 2, …). There are many ways to implement this, but the simplest and fastest is with a leader who chooses the ordering of values provided to it. As long as the leader remains alive, all followers need to only copy the values and ordering, the leader chooses.
Of course if leaders didn't fail we wouldn't need followers! When the leader does die we need to choose a new leader from among the followers. But followers themselves may fall behind or crash so we must ensure we choose an up-to-date follower. The fundamental guarantee a log replication algorithm must provide is that if we tell the client a message is committed, and the leader fails, the new leader we elect must also have that message. This yields a tradeoff: if the leader waits for more followers to acknowledge a message before declaring it committed then there will be more potentially electable leaders.
If you choose the number of acknowledgements required and the number of logs that must be compared to elect a leader such that there is guaranteed to be an overlap, then this is called a Quorum.
A common approach to this tradeoff is to use a majority vote for both the commit decision and the leader election. This is not what Kafka does, but let's explore it anyway to understand the tradeoffs. Let's say we have 2f+1 replicas. If f+1 replicas must receive a message prior to a commit being declared by the leader, and if we elect a new leader by electing the follower with the most complete log from at least f+1 replicas, then, with no more than f failures, the leader is guaranteed to have all committed messages. This is because among any f+1 replicas, there must be at least one replica that contains all committed messages. That replica's log will be the most complete and therefore will be selected as the new leader. There are many remaining details that each algorithm must handle (such as precisely defined what makes a log more complete, ensuring log consistency during leader failure or changing the set of servers in the replica set) but we will ignore these for now.
This majority vote approach has a very nice property: the latency is dependent on only the fastest servers. That is, if the replication factor is three, the latency is determined by the faster slave not the slower one.
There are a rich variety of algorithms in this family including ZooKeeper's Zab, Raft, and Viewstamped Replication. The most similar academic publication we are aware of to Kafka's actual implementation is PacificA from Microsoft.
The downside of majority vote is that it doesn't take many failures to leave you with no electable leaders. To tolerate one failure requires three copies of the data, and to tolerate two failures requires five copies of the data. In our experience having only enough redundancy to tolerate a single failure is not enough for a practical system, but doing every write five times, with 5x the disk space requirements and 1/5th the throughput, is not very practical for large volume data problems. This is likely why quorum algorithms more commonly appear for shared cluster configuration such as ZooKeeper but are less common for primary data storage. For example in HDFS the namenode's high-availability feature is built on a majority-vote-based journal, but this more expensive approach is not used for the data itself.
Kafka takes a slightly different approach to choosing its quorum set. Instead of majority vote, Kafka dynamically maintains a set of in-sync replicas (ISR) that are caught-up to the leader. Only members of this set are eligible for election as leader. A write to a Kafka partition is not considered committed until all in-sync replicas have received the write. This ISR set is persisted to ZooKeeper whenever it changes. Because of this, any replica in the ISR is eligible to be elected leader. This is an important factor for Kafka's usage model where there are many partitions and ensuring leadership balance is important. With this ISR model and f+1 replicas, a Kafka topic can tolerate f failures without losing committed messages.
For most use cases we hope to handle, we think this tradeoff is a reasonable one. In practice, to tolerate f failures, both the majority vote and the ISR approach will wait for the same number of replicas to acknowledge before committing a message (e.g. to survive one failure a majority quorum needs three replicas and one acknowledgement and the ISR approach requires two replicas and one acknowledgement). The ability to commit without the slowest servers is an advantage of the majority vote approach. However, we think it is ameliorated by allowing the client to choose whether they block on the message commit or not, and the additional throughput and disk space due to the lower required replication factor is worth it.
Another important design distinction is that Kafka does not require that crashed nodes recover with all their data intact. It is not uncommon for replication algorithms in this space to depend on the existence of "stable storage" that cannot be lost in any failure-recovery scenario without potential consistency violations. There are two primary problems with this assumption. First, disk errors are the most common problem we observe in real operation of persistent data systems and they often do not leave data intact. Secondly, even if this were not a problem, we do not want to require the use of fsync on every write for our consistency guarantees as this can reduce performance by two to three orders of magnitude. Our protocol for allowing a replica to rejoin the ISR ensures that before rejoining, it must fully re-sync again even if it lost unflushed data in its crash.
Unclean leader election: What if they all die?
Note that Kafka's guarantee with respect to data loss is predicated on at least on replica remaining in sync. If all the nodes replicating a partition die, this guarantee no longer holds.
However a practical system needs to do something reasonable when all the replicas die. If you are unlucky enough to have this occur, it is important to consider what will happen. There are two behaviors that could be implemented:
- Wait for a replica in the ISR to come back to life and choose this replica as the leader (hopefully it still has all its data).
- Choose the first replica (not necessarily in the ISR) that comes back to life as the leader.
This is a simple tradeoff between availability and consistency. If we wait for replicas in the ISR, then we will remain unavailable as long as those replicas are down. If such replicas were destroyed or their data was lost, then we are permanently down. If, on the other hand, a non-in-sync replica comes back to life and we allow it to become leader, then its log becomes the source of truth even though it is not guaranteed to have every committed message. In our current release we choose the second strategy and favor choosing a potentially inconsistent replica when all replicas in the ISR are dead. In the future, we would like to make this configurable to better support use cases where downtime is preferable to inconsistency.
This dilemma is not specific to Kafka. It exists in any quorum-based scheme. For example in a majority voting scheme, if a majority of servers suffer a permanent failure, then you must either choose to lose 100% of your data or violate consistency by taking what remains on an existing server as your new source of truth.
Availability and Durability Guarantees
When writing to Kafka, producers can choose whether they wait for the message to be acknowledged by 0,1 or all (-1) replicas. Note that "acknowledgement by all replicas" does not guarantee that the full set of assigned replicas have received the message. By default, when request.required.acks=-1, acknowledgement happens as soon as all the current in-sync replicas have received the message. For example, if a topic is configured with only two replicas and one fails (i.e., only one in sync replica remains), then writes that specify request.required.acks=-1 will succeed. However, these writes could be lost if the remaining replica also fails. Although this ensures maximum availability of the partition, this behavior may be undesirable to some users who prefer durability over availability. Therefore, we provide two topic-level configurations that can be used to prefer message durability over availability:
- Disable unclean leader election - if all replicas become unavailable, then the partition will remain unavailable until the most recent leader becomes available again. This effectively prefers unavailability over the risk of message loss. See the previous section on Unclean Leader Election for clarification.
- Specify a minimum ISR size - the partition will only accept writes if the size of the ISR is above a certain minimum, in order to prevent the loss of messages that were written to just a single replica, which subsequently becomes unavailable. This setting only takes effect if the producer uses required.acks=-1 and guarantees that the message will be acknowledged by at least this many in-sync replicas. This setting offers a trade-off between consistency and availability. A higher setting for minimum ISR size guarantees better consistency since the message is guaranteed to be written to more replicas which reduces the probability that it will be lost. However, it reduces availability since the partition will be unavailable for writes if the number of in-sync replicas drops below the minimum threshold.
Replica Management
The above discussion on replicated logs really covers only a single log, i.e. one topic partition. However a Kafka cluster will manage hundreds or thousands of these partitions. We attempt to balance partitions within a cluster in a round-robin fashion to avoid clustering all partitions for high-volume topics on a small number of nodes. Likewise we try to balance leadership so that each node is the leader for a proportional share of its partitions.
It is also important to optimize the leadership election process as that is the critical window of unavailability. A naive implementation of leader election would end up running an election per partition for all partitions a node hosted when that node failed. Instead, we elect one of the brokers as the "controller". This controller detects failures at the broker level and is responsible for changing the leader of all affected partitions in a failed broker. The result is that we are able to batch together many of the required leadership change notifications which makes the election process far cheaper and faster for a large number of partitions. If the controller fails, one of the surviving brokers will become the new controller.
4.8 Log Compaction
Log compaction ensures that Kafka will always retain at least the last known value for each message key within the log of data for a single topic partition. It addresses use cases and scenarios such as restoring state after application crashes or system failure, or reloading caches after application restarts during operational maintenance. Let's dive into these use cases in more detail and then describe how compaction works.
So far we have described only the simpler approach to data retention where old log data is discarded after a fixed period of time or when the log reaches some predetermined size. This works well for temporal event data such as logging where each record stands alone. However an important class of data streams are the log of changes to keyed, mutable data (for example, the changes to a database table).
Let's discuss a concrete example of such a stream. Say we have a topic containing user email addresses; every time a user updates their email address we send a message to this topic using their user id as the primary key. Now say we send the following messages over some time period for a user with id 123, each message corresponding to a change in email address (messages for other ids are omitted):
123 => bill@microsoft.com
.
.
.
123 => bill@gatesfoundation.org
.
.
.
123 => bill@gmail.com
Log compaction gives us a more granular retention mechanism so that we are guaranteed to retain at least the last update for each primary key (e.g. bill@gmail.com). By doing this we guarantee that the log contains a full snapshot of the final value for every key not just keys that changed recently. This means downstream consumers can restore their own state off this topic without us having to retain a complete log of all changes.
Let's start by looking at a few use cases where this is useful, then we'll see how it can be used.
- Database change subscription. It is often necessary to have a data set in multiple data systems, and often one of these systems is a database of some kind (either a RDBMS or perhaps a new-fangled key-value store). For example you might have a database, a cache, a search cluster, and a Hadoop cluster. Each change to the database will need to be reflected in the cache, the search cluster, and eventually in Hadoop. In the case that one is only handling the real-time updates you only need recent log. But if you want to be able to reload the cache or restore a failed search node you may need a complete data set.
- Event sourcing. This is a style of application design which co-locates query processing with application design and uses a log of changes as the primary store for the application.
- Journaling for high-availability. A process that does local computation can be made fault-tolerant by logging out changes that it makes to it's local state so another process can reload these changes and carry on if it should fail. A concrete example of this is handling counts, aggregations, and other "group by"-like processing in a stream query system. Samza, a real-time stream-processing framework, uses this feature for exactly this purpose.
In each of these cases one needs primarily to handle the real-time feed of changes, but occasionally, when a machine crashes or data needs to be re-loaded or re-processed, one needs to do a full load. Log compaction allows feeding both of these use cases off the same backing topic. This style of usage of a log is described in more detail in this blog post.
The general idea is quite simple. If we had infinite log retention, and we logged each change in the above cases, then we would have captured the state of the system at each time from when it first began. Using this complete log we could restore to any point in time by replaying the first N records in the log. This hypothetical complete log is not very practical for systems that update a single record many times as the log will grow without bound even for a stable dataset. The simple log retention mechanism which throws away old updates will bound space but the log is no longer a way to restore the current state—now restoring from the beginning of the log no longer recreates the current state as old updates may not be captured at all.
Log compaction is a mechanism to give finer-grained per-record retention, rather than the coarser-grained time-based retention. The idea is to selectively remove records where we have a more recent update with the same primary key. This way the log is guaranteed to have at least the last state for each key.
This retention policy can be set per-topic, so a single cluster can have some topics where retention is enforced by size or time and other topics where retention is enforced by compaction.
This functionality is inspired by one of LinkedIn's oldest and most successful pieces of infrastructure—a database changelog caching service called Databus. Unlike most log-structured storage systems Kafka is built for subscription and organizes data for fast linear reads and writes. Unlike Databus, Kafka acts a source-of-truth store so it is useful even in situations where the upstream data source would not otherwise be replayable.
Log Compaction Basics
Here is a high-level picture that shows the logical structure of a Kafka log with the offset for each message.
The head of the log is identical to a traditional Kafka log. It has dense, sequential offsets and retains all messages. Log compaction adds an option for handling the tail of the log. The picture above shows a log with a compacted tail. Note that the messages in the tail of the log retain the original offset assigned when they were first written—that never changes. Note also that all offsets remain valid positions in the log, even if the message with that offset has been compacted away; in this case this position is indistinguishable from the next highest offset that does appear in the log. For example, in the picture above the offsets 36, 37, and 38 are all equivalent positions and a read beginning at any of these offsets would return a message set beginning with 38.
Compaction also allows for deletes. A message with a key and a null payload will be treated as a delete from the log. This delete marker will cause any prior message with that key to be removed (as would any new message with that key), but delete markers are special in that they will themselves be cleaned out of the log after a period of time to free up space. The point in time at which deletes are no longer retained is marked as the "delete retention point" in the above diagram.
The compaction is done in the background by periodically recopying log segments. Cleaning does not block reads and can be throttled to use no more than a configurable amount of I/O throughput to avoid impacting producers and consumers. The actual process of compacting a log segment looks something like this:
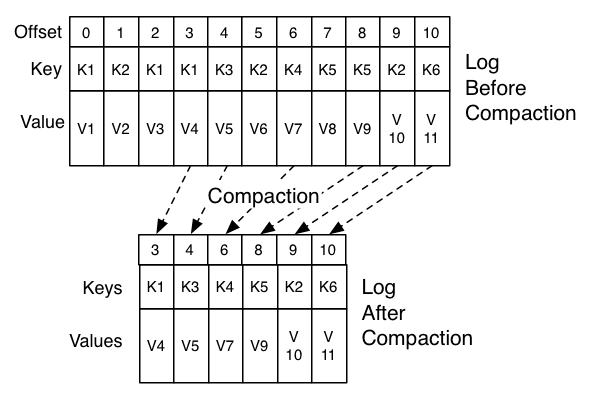
What guarantees does log compaction provide?
Log compaction guarantees the following:
- Any consumer that stays caught-up to within the head of the log will see every message that is written; these messages will have sequential offsets.
- Ordering of messages is always maintained. Compaction will never re-order messages, just remove some.
- The offset for a message never changes. It is the permanent identifier for a position in the log.
- Any read progressing from offset 0 will see at least the final state of all records in the order they were written. All delete markers for deleted records will be seen provided the reader reaches the head of the log in a time period less than the topic's delete.retention.ms setting (the default is 24 hours). This is important as delete marker removal happens concurrently with read (and thus it is important that we not remove any delete marker prior to the reader seeing it).
- Any consumer progressing from the start of the log, will see at least the final state of all records in the order they were written. All delete markers for deleted records will be seen provided the consumer reaches the head of the log in a time period less than the topic's delete.retention.ms setting (the default is 24 hours). This is important as delete marker removal happens concurrently with read, and thus it is important that we do not remove any delete marker prior to the consumer seeing it.
Log Compaction Details
Log compaction is handled by the log cleaner, a pool of background threads that recopy log segment files, removing records whose key appears in the head of the log. Each compactor thread works as follows:
- It chooses the log that has the highest ratio of log head to log tail
- It creates a succinct summary of the last offset for each key in the head of the log
- It recopies the log from beginning to end removing keys which have a later occurrence in the log. New, clean segments are swapped into the log immediately so the additional disk space required is just one additional log segment (not a fully copy of the log).
- The summary of the log head is essentially just a space-compact hash table. It uses exactly 24 bytes per entry. As a result with 8GB of cleaner buffer one cleaner iteration can clean around 366GB of log head (assuming 1k messages).
Configuring The Log Cleaner
The log cleaner is disabled by default. To enable it set the server config
log.cleaner.enable=true
This will start the pool of cleaner threads. To enable log cleaning on a particular topic you can add the log-specific property
log.cleanup.policy=compact
This can be done either at topic creation time or using the alter topic command.
Further cleaner configurations are described here.
Log Compaction Limitations
- You cannot configure yet how much log is retained without compaction (the "head" of the log). Currently all segments are eligible except for the last segment, i.e. the one currently being written to.
- Log compaction is not yet compatible with compressed topics.
5 実装
5.1 API Design
Producer APIs
The Producer API that wraps the 2 low-level producers - kafka.producer.SyncProducer and kafka.producer.async.AsyncProducer.
class Producer { /* Sends the data, partitioned by key to the topic using either the */ /* synchronous or the asynchronous producer */ public void send(kafka.javaapi.producer.ProducerData<K,V> producerData); /* Sends a list of data, partitioned by key to the topic using either */ /* the synchronous or the asynchronous producer */ public void send(java.util.List<kafka.javaapi.producer.ProducerData<K,V>> producerData); /* Closes the producer and cleans up */ public void close(); }
The goal is to expose all the producer functionality through a single API to the client. The new producer -
- can handle queueing/buffering of multiple producer requests and asynchronous dispatch of the batched data -
kafka.producer.Producerprovides the ability to batch multiple produce requests (producer.type=async), before serializing and dispatching them to the appropriate kafka broker partition. The size of the batch can be controlled by a few config parameters. As events enter a queue, they are buffered in a queue, until eitherqueue.timeorbatch.sizeis reached. A background thread (kafka.producer.async.ProducerSendThread) dequeues the batch of data and lets thekafka.producer.EventHandlerserialize and send the data to the appropriate kafka broker partition. A custom event handler can be plugged in through theevent.handlerconfig parameter. At various stages of this producer queue pipeline, it is helpful to be able to inject callbacks, either for plugging in custom logging/tracing code or custom monitoring logic. This is possible by implementing thekafka.producer.async.CallbackHandlerinterface and settingcallback.handlerconfig parameter to that class. - handles the serialization of data through a user-specified
Encoder-interface Encoder<T> { public Message toMessage(T data); }
The default is the no-op
kafka.serializer.DefaultEncoder - provides software load balancing through an optionally user-specified
Partitioner-The routing decision is influenced by the
kafka.producer.Partitioner.interface Partitioner<T> { int partition(T key, int numPartitions); }
The partition API uses the key and the number of available broker partitions to return a partition id. This id is used as an index into a sorted list of broker_ids and partitions to pick a broker partition for the producer request. The default partitioning strategy is
hash(key)%numPartitions. If the key is null, then a random broker partition is picked. A custom partitioning strategy can also be plugged in using thepartitioner.classconfig parameter.
Consumer APIs
We have 2 levels of consumer APIs. The low-level "simple" API maintains a connection to a single broker and has a close correspondence to the network requests sent to the server. This API is completely stateless, with the offset being passed in on every request, allowing the user to maintain this metadata however they choose.
The high-level API hides the details of brokers from the consumer and allows consuming off the cluster of machines without concern for the underlying topology. It also maintains the state of what has been consumed. The high-level API also provides the ability to subscribe to topics that match a filter expression (i.e., either a whitelist or a blacklist regular expression).
Low-level API
class SimpleConsumer { /* Send fetch request to a broker and get back a set of messages. */ public ByteBufferMessageSet fetch(FetchRequest request); /* Send a list of fetch requests to a broker and get back a response set. */ public MultiFetchResponse multifetch(List<FetchRequest> fetches); /** * Get a list of valid offsets (up to maxSize) before the given time. * The result is a list of offsets, in descending order. * @param time: time in millisecs, * if set to OffsetRequest$.MODULE$.LATIEST_TIME(), get from the latest offset available. * if set to OffsetRequest$.MODULE$.EARLIEST_TIME(), get from the earliest offset available. */ public long[] getOffsetsBefore(String topic, int partition, long time, int maxNumOffsets); }
The low-level API is used to implement the high-level API as well as being used directly for some of our offline consumers (such as the hadoop consumer) which have particular requirements around maintaining state.
High-level API
/* create a connection to the cluster */ ConsumerConnector connector = Consumer.create(consumerConfig); interface ConsumerConnector { /** * This method is used to get a list of KafkaStreams, which are iterators over * MessageAndMetadata objects from which you can obtain messages and their * associated metadata (currently only topic). * Input: a map of <topic, #streams> * Output: a map of <topic, list of message streams> */ public Map<String,List<KafkaStream>> createMessageStreams(Map<String,Int> topicCountMap); /** * You can also obtain a list of KafkaStreams, that iterate over messages * from topics that match a TopicFilter. (A TopicFilter encapsulates a * whitelist or a blacklist which is a standard Java regex.) */ public List<KafkaStream> createMessageStreamsByFilter( TopicFilter topicFilter, int numStreams); /* Commit the offsets of all messages consumed so far. */ public commitOffsets() /* Shut down the connector */ public shutdown() }
This API is centered around iterators, implemented by the KafkaStream class. Each KafkaStream represents the stream of messages from one or more partitions on one or more servers. Each stream is used for single threaded processing, so the client can provide the number of desired streams in the create call. Thus a stream may represent the merging of multiple server partitions (to correspond to the number of processing threads), but each partition only goes to one stream.
The createMessageStreams call registers the consumer for the topic, which results in rebalancing the consumer/broker assignment. The API encourages creating many topic streams in a single call in order to minimize this rebalancing. The createMessageStreamsByFilter call (additionally) registers watchers to discover new topics that match its filter. Note that each stream that createMessageStreamsByFilter returns may iterate over messages from multiple topics (i.e., if multiple topics are allowed by the filter).
5.2 Network Layer
The network layer is a fairly straight-forward NIO server, and will not be described in great detail. The sendfile implementation is done by giving the MessageSet interface a writeTo method.
This allows the file-backed message set to use the more efficient transferTo implementation instead of an in-process buffered write. The threading model is a single acceptor thread and N processor threads which handle a fixed number of connections each. This design has been pretty thoroughly tested elsewhere and found to be simple to implement and fast. The protocol is kept quite simple to allow for future implementation of clients in other languages.
5.3 Messages
Messages consist of a fixed-size header and variable length opaque byte array payload. The header contains a format version and a CRC32 checksum to detect corruption or truncation. Leaving the payload opaque is the right decision: there is a great deal of progress being made on serialization libraries right now, and any particular choice is unlikely to be right for all uses. Needless to say a particular application using Kafka would likely mandate a particular serialization type as part of its usage. The MessageSet interface is simply an iterator over messages with specialized methods for bulk reading and writing to an NIO Channel.
5.4 Message Format
/** * A message. The format of an N byte message is the following: * * If magic byte is 0 * * 1. 1 byte "magic" identifier to allow format changes * * 2. 4 byte CRC32 of the payload * * 3. N - 5 byte payload * * If magic byte is 1 * * 1. 1 byte "magic" identifier to allow format changes * * 2. 1 byte "attributes" identifier to allow annotations on the message independent of the version (e.g. compression enabled, type of codec used) * * 3. 4 byte CRC32 of the payload * * 4. N - 6 byte payload * */
5.5 Log
A log for a topic named "my_topic" with two partitions consists of two directories (namely my_topic_0 and my_topic_1) populated with data files containing the messages for that topic. The format of the log files is a sequence of "log entries""; each log entry is a 4 byte integer N storing the message length which is followed by the N message bytes. Each message is uniquely identified by a 64-bit integer offset giving the byte position of the start of this message in the stream of all messages ever sent to that topic on that partition. The on-disk format of each message is given below. Each log file is named with the offset of the first message it contains. So the first file created will be 00000000000.kafka, and each additional file will have an integer name roughly S bytes from the previous file where S is the max log file size given in the configuration.
The exact binary format for messages is versioned and maintained as a standard interface so message sets can be transfered between producer, broker, and client without recopying or conversion when desirable. This format is as follows:
On-disk format of a message message length : 4 bytes (value: 1+4+n) "magic" value : 1 byte crc : 4 bytes payload : n bytes
The use of the message offset as the message id is unusual. Our original idea was to use a GUID generated by the producer, and maintain a mapping from GUID to offset on each broker. But since a consumer must maintain an ID for each server, the global uniqueness of the GUID provides no value. Furthermore the complexity of maintaining the mapping from a random id to an offset requires a heavy weight index structure which must be synchronized with disk, essentially requiring a full persistent random-access data structure. Thus to simplify the lookup structure we decided to use a simple per-partition atomic counter which could be coupled with the partition id and node id to uniquely identify a message; this makes the lookup structure simpler, though multiple seeks per consumer request are still likely. However once we settled on a counter, the jump to directly using the offset seemed natural—both after all are monotonically increasing integers unique to a partition. Since the offset is hidden from the consumer API this decision is ultimately an implementation detail and we went with the more efficient approach.
Writes
The log allows serial appends which always go to the last file. This file is rolled over to a fresh file when it reaches a configurable size (say 1GB). The log takes two configuration parameter M which gives the number of messages to write before forcing the OS to flush the file to disk, and S which gives a number of seconds after which a flush is forced. This gives a durability guarantee of losing at most M messages or S seconds of data in the event of a system crash.
Reads
Reads are done by giving the 64-bit logical offset of a message and an S-byte max chunk size. This will return an iterator over the messages contained in the S-byte buffer. S is intended to be larger than any single message, but in the event of an abnormally large message, the read can be retried multiple times, each time doubling the buffer size, until the message is read successfully. A maximum message and buffer size can be specified to make the server reject messages larger than some size, and to give a bound to the client on the maximum it need ever read to get a complete message. It is likely that the read buffer ends with a partial message, this is easily detected by the size delimiting.
The actual process of reading from an offset requires first locating the log segment file in which the data is stored, calculating the file-specific offset from the global offset value, and then reading from that file offset. The search is done as a simple binary search variation against an in-memory range maintained for each file.
The log provides the capability of getting the most recently written message to allow clients to start subscribing as of "right now". This is also useful in the case the consumer fails to consume its data within its SLA-specified number of days. In this case when the client attempts to consume a non-existant offset it is given an OutOfRangeException and can either reset itself or fail as appropriate to the use case.
The following is the format of the results sent to the consumer.
MessageSetSend (fetch result) total length : 4 bytes error code : 2 bytes message 1 : x bytes ... message n : x bytes MultiMessageSetSend (multiFetch result) total length : 4 bytes error code : 2 bytes messageSetSend 1 ... messageSetSend n
Deletes
Data is deleted one log segment at a time. The log manager allows pluggable delete policies to choose which files are eligible for deletion. The current policy deletes any log with a modification time of more than N days ago, though a policy which retained the last N GB could also be useful. To avoid locking reads while still allowing deletes that modify the segment list we use a copy-on-write style segment list implementation that provides consistent views to allow a binary search to proceed on an immutable static snapshot view of the log segments while deletes are progressing.
Guarantees
The log provides a configuration parameter M which controls the maximum number of messages that are written before forcing a flush to disk. On startup a log recovery process is run that iterates over all messages in the newest log segment and verifies that each message entry is valid. A message entry is valid if the sum of its size and offset are less than the length of the file AND the CRC32 of the message payload matches the CRC stored with the message. In the event corruption is detected the log is truncated to the last valid offset.
Note that two kinds of corruption must be handled: truncation in which an unwritten block is lost due to a crash, and corruption in which a nonsense block is ADDED to the file. The reason for this is that in general the OS makes no guarantee of the write order between the file inode and the actual block data so in addition to losing written data the file can gain nonsense data if the inode is updated with a new size but a crash occurs before the block containing that data is not written. The CRC detects this corner case, and prevents it from corrupting the log (though the unwritten messages are, of course, lost).
5.6 Distribution
Consumer Offset Tracking
The high-level consumer tracks the maximum offset it has consumed in each partition and periodically commits its offset vector so that it can resume from those offsets in the event of a restart. Kafka provides the option to store all the offsets for a given consumer group in a designated broker (for that group) called the offset manager. i.e., any consumer instance in that consumer group should send its offset commits and fetches to that offset manager (broker). The high-level consumer handles this automatically. If you use the simple consumer you will need to manage offsets manually. This is currently unsupported in the Java simple consumer which can only commit or fetch offsets in ZooKeeper. If you use the Scala simple consumer you can discover the offset manager and explicitly commit or fetch offsets to the offset manager. A consumer can look up its offset manager by issuing a ConsumerMetadataRequest to any Kafka broker and reading the ConsumerMetadataResponse which will contain the offset manager. The consumer can then proceed to commit or fetch offsets from the offsets manager broker. In case the offset manager moves, the consumer will need to rediscover the offset manager. If you wish to manage your offsets manually, you can take a look at these code samples that explain how to issue OffsetCommitRequest and OffsetFetchRequest.
When the offset manager receives an OffsetCommitRequest, it appends the request to a special compacted Kafka topic named __consumer_offsets. The offset manager sends a successful offset commit response to the consumer only after all the replicas of the offsets topic receive the offsets. In case the offsets fail to replicate within a configurable timeout, the offset commit will fail and the consumer may retry the commit after backing off. (This is done automatically by the high-level consumer.) The brokers periodically compact the offsets topic since it only needs to maintain the most recent offset commit per partition. The offset manager also caches the offsets in an in-memory table in order to serve offset fetches quickly.
Migrating offsets from ZooKeeper to Kafka
Kafka consumers in earlier releases store their offsets by default in ZooKeeper. It is possible to migrate these consumers to commit offsets into Kafka by following these steps:
- Set
offsets.storage=kafkaanddual.commit.enabled=truein your consumer config. - Do a rolling bounce of your consumers and then verify that your consumers are healthy.
- Set
dual.commit.enabled=falsein your consumer config. - Do a rolling bounce of your consumers and then verify that your consumers are healthy.
A roll-back (i.e., migrating from Kafka back to ZooKeeper) can also be performed using the above steps if you set offsets.storage=zookeeper.
ZooKeeper Directories
The following gives the ZooKeeper structures and algorithms used for co-ordination between consumers and brokers.
Notation
When an element in a path is denoted [xyz], that means that the value of xyz is not fixed and there is in fact a ZooKeeper znode for each possible value of xyz. For example /topics/[topic] would be a directory named /topics containing a sub-directory for each topic name. Numerical ranges are also given such as [0…5] to indicate the subdirectories 0, 1, 2, 3, 4. An arrow -> is used to indicate the contents of a znode. For example /hello -> world would indicate a znode /hello containing the value "world".
Broker Node Registry
/brokers/ids/[0...N] --> host:port (ephemeral node)
This is a list of all present broker nodes, each of which provides a unique logical broker id which identifies it to consumers (which must be given as part of its configuration). On startup, a broker node registers itself by creating a znode with the logical broker id under /brokers/ids. The purpose of the logical broker id is to allow a broker to be moved to a different physical machine without affecting consumers. An attempt to register a broker id that is already in use (say because two servers are configured with the same broker id) is an error.
Since the broker registers itself in ZooKeeper using ephemeral znodes, this registration is dynamic and will disappear if the broker is shutdown or dies (thus notifying consumers it is no longer available).
Broker Topic Registry
/brokers/topics/[topic]/[0...N] --> nPartions (ephemeral node)
Each broker registers itself under the topics it maintains and stores the number of partitions for that topic.
Consumers and Consumer Groups
Consumers of topics also register themselves in ZooKeeper, in order to coordinate with each other and balance the consumption of data. Consumers can also store their offsets in ZooKeeper by setting offsets.storage=zookeeper. However, this offset storage mechanism will be deprecated in a future release. Therefore, it is recommended to migrate offsets storage to Kafka.
Multiple consumers can form a group and jointly consume a single topic. Each consumer in the same group is given a shared group_id. For example if one consumer is your foobar process, which is run across three machines, then you might assign this group of consumers the id "foobar". This group id is provided in the configuration of the consumer, and is your way to tell the consumer which group it belongs to.
The consumers in a group divide up the partitions as fairly as possible, each partition is consumed by exactly one consumer in a consumer group.
Consumer Id Registry
In addition to the group_id which is shared by all consumers in a group, each consumer is given a transient, unique consumer_id (of the form hostname:uuid) for identification purposes. Consumer ids are registered in the following directory.
/consumers/[group_id]/ids/[consumer_id] --> {"topic1": #streams, ..., "topicN": #streams} (ephemeral node)
Each of the consumers in the group registers under its group and creates a znode with its consumer_id. The value of the znode contains a map of <topic, #streams>. This id is simply used to identify each of the consumers which is currently active within a group. This is an ephemeral node so it will disappear if the consumer process dies.
Consumer Offsets
Consumers track the maximum offset they have consumed in each partition. This value is stored in a ZooKeeper directory if offsets.storage=zookeeper. This valued is stored in a ZooKeeper directory.
/consumers/[group_id]/offsets/[topic]/[broker_id-partition_id] --> offset_counter_value ((persistent node)
Partition Owner registry
Each broker partition is consumed by a single consumer within a given consumer group. The consumer must establish its ownership of a given partition before any consumption can begin. To establish its ownership, a consumer writes its own id in an ephemeral node under the particular broker partition it is claiming.
/consumers/[group_id]/owners/[topic]/[broker_id-partition_id] --> consumer_node_id (ephemeral node)
Broker node registration
The broker nodes are basically independent, so they only publish information about what they have. When a broker joins, it registers itself under the broker node registry directory and writes information about its host name and port. The broker also register the list of existing topics and their logical partitions in the broker topic registry. New topics are registered dynamically when they are created on the broker.
Consumer registration algorithm
When a consumer starts, it does the following:
- Register itself in the consumer id registry under its group.
- Register a watch on changes (new consumers joining or any existing consumers leaving) under the consumer id registry. (Each change triggers rebalancing among all consumers within the group to which the changed consumer belongs.)
- Register a watch on changes (new brokers joining or any existing brokers leaving) under the broker id registry. (Each change triggers rebalancing among all consumers in all consumer groups.)
- If the consumer creates a message stream using a topic filter, it also registers a watch on changes (new topics being added) under the broker topic registry. (Each change will trigger re-evaluation of the available topics to determine which topics are allowed by the topic filter. A new allowed topic will trigger rebalancing among all consumers within the consumer group.)
- Force itself to rebalance within in its consumer group.
Consumer rebalancing algorithm
The consumer rebalancing algorithms allows all the consumers in a group to come into consensus on which consumer is consuming which partitions. Consumer rebalancing is triggered on each addition or removal of both broker nodes and other consumers within the same group. For a given topic and a given consumer group, broker partitions are divided evenly among consumers within the group. A partition is always consumed by a single consumer. This design simplifies the implementation. Had we allowed a partition to be concurrently consumed by multiple consumers, there would be contention on the partition and some kind of locking would be required. If there are more consumers than partitions, some consumers won't get any data at all. During rebalancing, we try to assign partitions to consumers in such a way that reduces the number of broker nodes each consumer has to connect to.
Each consumer does the following during rebalancing:
1. For each topic T that Ci subscribes to
2. let PT be all partitions producing topic T
3. let CG be all consumers in the same group as Ci that consume topic T
4. sort PT (so partitions on the same broker are clustered together)
5. sort CG
6. let i be the index position of Ci in CG and let N = size(PT)/size(CG)
7. assign partitions from i*N to (i+1)*N - 1 to consumer Ci
8. remove current entries owned by Ci from the partition owner registry
9. add newly assigned partitions to the partition owner registry
(we may need to re-try this until the original partition owner releases its ownership)
When rebalancing is triggered at one consumer, rebalancing should be triggered in other consumers within the same group about the same time.
6 運用
▶ show original text
Operation
Here is some information on actually running Kafka as a production system based on usage and experience at LinkedIn. Please send us any additional tips you know of.
LinkedInでの使用例や実績をもとに、実際にKafkaを商用システムで稼動させるにあたっての情報を載せていま す。追加情報があればご連絡下さい。
6.1 Kafkaの基本的な運用
▶ show original text
Basic Kafka Operations
This section will review the most common operations you will perform on your Kafka cluster. All of
the tools reviewed in this section are available under the bin/ directory of the Kafka
distribution and each tool will print details on all possible commandline options if it is run with
no arguments.
本節では、一般的なKafkaクラスタの運用について述べます。
言及されているツールは全てKafkaの bin/ ディレクトリ以下に配置されており、
引数無しでそれらのツールを実行することで詳細を確認することが出来ます。
Adding and removing topics
▶ show original text
Adding and removing topics
You have the option of either adding topics manually or having them be created automatically when data is first published to a non-existent topic. If topics are auto-created then you may want to tune the default topic configurations used for auto-created topics.
トピックの追加と削除
トピックは手動で作成する方法と、 初回のパブリッシュ時に存在しなかった場合に自動で作成させる方法があります。 トピックの自動作成時は、デフォルトの トピックの設定値 がトピックの設定として利用されるため、 調整しましょう。
▶ show original text
Topics are added and modified using the topic tool:
付属のトピックツールを使ってトピックの作成及び修正が出来ます:
> bin/kafka-topics.sh --zookeeper zk_host:port/chroot --create --topic my_topic_name --partitions 20 --replication-factor 3 --config x=y
▶ show original text
The replication factor controls how many servers will replicate each message that is written. If you have a replication factor of 3 then up to 2 servers can fail before you will lose access to your data. We recommend you use a replication factor of 2 or 3 so that you can transparently bounce machines without interrupting data consumption.
レプリケーションファクタは書き込まれる各メッセージについて、 いくつのサーバに複製を作成するかを制御します。 レプリケーションファクタが3の場合、サーバに障害が発生しても最大2つまでは データにアクセスすることが出来ます。
▶ show original text
The partition count controls how many logs the topic will be sharded into. There are several impacts of the partition count. First each partition must fit entirely on a single server. So if you have 20 partitions the full data set (and read and write load) will be handled by no more than 20 servers (no counting replicas). Finally the partition count impacts the maximum parallelism of your consumers. This is discussed in greater detail in the concepts section.
パーティション数はトピックをいくつのログにシャーディングするかを制御します。 パーティション数の影響を受けるものはいくつかあります。 まず、各パーティションは一つのサーバに全体が収まるようにしなければなりません。 そのため20パーティションの場合、データセット全体(そして読み書きの負荷)は 20台よりも多いサーバに分散することはありません(複製は除く)。 そして、パーティション数はコンシューマの最大並列度に影響を与えます。 より詳細な議論は コンセプトの節 を参照してください。
▶ show original text
The configurations added on the command line override the default settings the server has for things like the length of time data should be retained. The complete set of per-topic configurations is documented here.
コマンドラインで与えられた設定は、データ保持期間等のサーバ側のデフォルト設定を上書きします。 トピック毎の設定については こちら を参照してください。
トピックの修正
▶ show original text
Modifying topics
You can change the configuration or partitioning of a topic using the same topic tool.
同じトピックツールを利用して設定やパーティションを変更することも出来ます。
▶ show original text
To add partitions you can do
パーティションを追加するには以下のようにします
> bin/kafka-topics.sh --zookeeper zk_host:port/chroot --alter --topic my_topic_name --partitions 40
▶ show original text
Be aware that one use case for partitions is to semantically partition data, and adding partitions
doesn't change the partitioning of existing data so this may disturb consumers if they rely on that
partition. That is if data is partitioned by hash(key) % number_of_partitions then this
partitioning will potentially be shuffled by adding partitions but Kafka will not attempt to
automatically redistribute data in any way.
意味的にデータを分割するというのがパーティションの利用ケースのひとつとして考えられますが、
パーティションを追加しても既存のデータは変更されない為、
コンシューマがパーティション構成に依存している場合は混乱を生じる可能性があることに注意して下さい。
つまり、例えばデータが ハッシュ関数(key) % パーティション数 という法則で分割されていた場合、
パーティションを追加によってデータの配置場所が滅茶苦茶になる可能性があります。
Kafkaは自動的にデータを再配布しようとすることは決してありません。
▶ show original text
To add configs:
設定を追加するには:
> bin/kafka-topics.sh --zookeeper zk_host:port/chroot --alter --topic my_topic_name --config x=y
▶ show original text
To remove a config:
設定を削除するには:
> bin/kafka-topics.sh --zookeeper zk_host:port/chroot --alter --topic my_topic_name --deleteConfig x
▶ show original text
And finally deleting a topic:
トピックを削除するには:
> bin/kafka-topics.sh --zookeeper zk_host:port/chroot --delete --topic my_topic_name
▶ show original text
Topic deletion option is disabled by default. To enable it set the server config
トピックはデフォルトでは削除出来ないように設定されています。 削除可能にするには以下のサーバ設定を追加してください。
delete.topic.enable=true
▶ show original text
Kafka does not currently support reducing the number of partitions for a topic or changing the replication factor.
Kafkaは現在パーティション数やレプリケーションファクタを減らすことはサポートしていません。
緩やかなシャットダウン
▶ show original text
Graceful shutdown
The Kafka cluster will automatically detect any broker shutdown or failure and elect new leaders for the partitions on that machine. This will occur whether a server fails or it is brought down intentionally for maintenance or configuration changes. For the later cases Kafka supports a more graceful mechanism for stoping a server then just killing it. When a server is stopped gracefully it has two optimizations it will take advantage of:
Kafkaクラスタは自動的にブローカのシャットダウンや障害を検知し、 対象のブローカが担当していたパーティションに対する新たなリーダを選びます。 新たなリーダの選択は、サーバの障害時、あるいはメンテナンスや設定変更の為に意図的に落とした場合、 両方の場合に同様に発生します。 後者の場合は、単にサーバを落とすよりもより緩やかに停止するための機構をサポートしています。 緩やかに停止する場合は以下の利点が得られるように2つの最適化が行なわれます:
▶ show original text
- It will sync all its logs to disk to avoid needing to do any log recovery when it restarts (i.e. validating the checksum for all messages in the tail of the log). Log recovery takes time so this speeds up intentional restarts.
- It will migrate any partitions the server is the leader for to other replicas prior to shutting down. This will make the leadership transfer faster and minimize the time each partition is unavailable to a few milliseconds.
- 保持している全てのログをディスクに同期し、再起動時のログリカバリ(ログ末尾の全メッセージについてチェックサムを検証する)を不要にします 15
- 自身がリーダとなっている全パーティションを、シャットダウン前に他の複製に移行します。 これにより速やかにリーダ権を移行でき、各パーティションへのアクセス不能時間を数ミリ秒にまで最小化出来ます。
▶ show original text
Syncing the logs will happen automatically happen whenever the server is stopped other than by a hard kill, but the controlled leadership migration requires using a special setting:
ログの同期は強制シャットダウン以外の場合は自動的に行なわれますが、 制御されたリーダ権の移行は特別な設定が必要です:
controlled.shutdown.enable=true
▶ show original text
Note that controlled shutdown will only succeed if all the partitions hosted on the broker have replicas (i.e. the replication factor is greater than 1 and at least one of these replicas is alive). This is generally what you want since shutting down the last replica would make that topic partition unavailable.
制御されたシャットダウンは、 そのブローカが保持する 全ての パーティションが複製を持つ場合に限り成功します (つまり、レプリケーションファクタが2以上で かつ そのうち最低1つの複製が生存している場合)。 最後の複製をシャットダウンしてしまえばそのトピックはアクセス不能になってしまうため、 このことは通常は問題にならないでしょう。
リーダ権のバランシング
▶ show original text
Balancing leadership
Whenever a broker stops or crashes leadership for that broker's partitions transfers to other replicas. This means that by default when the broker is restarted it will only be a follower for all its partitions, meaning it will not be used for client reads and writes.
ブローカが停止したりクラッシュした場合は常に、 そのブローカのパーティションのリーダ権の他の複製への移行が行われます。 つまりデフォルトではブローカが再起動した場合、 全パーティションについてフォロワにしかならず、 クライアントからの読み書きに利用されなくなるということを意味します。
To avoid this imbalance, Kafka has a notion of preferred replicas. If the list of replicas for a partition is 1,5,9 then node 1 is preferred as the leader to either node 5 or 9 because it is earlier in the replica list. You can have the Kafka cluster try to restore leadership to the restored replicas by running the command:
> bin/kafka-preferred-replica-election.sh --zookeeper zk_host:port/chroot
Since running this command can be tedious you can also configure Kafka to do this automatically by setting the following configuration:
auto.leader.rebalance.enable=true
Mirroring data between clusters
We refer to the process of replicating data between Kafka clusters "mirroring" to avoid confusion with the replication that happens amongst the nodes in a single cluster. Kafka comes with a tool for mirroring data between Kafka clusters. The tool reads from one or more source clusters and writes to a destination cluster, like this:
A common use case for this kind of mirroring is to provide a replica in another datacenter. This scenario will be discussed in more detail in the next section.
You can run many such mirroring processes to increase throughput and for fault-tolerance (if one process dies, the others will take overs the additional load).
Data will be read from topics in the source cluster and written to a topic with the same name in the destination cluster. In fact the mirror maker is little more than a Kafka consumer and producer hooked together.
The source and destination clusters are completely independent entities: they can have different numbers of partitions and the offsets will not be the same. For this reason the mirror cluster is not really intended as a fault-tolerance mechanism (as the consumer position will be different); for that we recommend using normal in-cluster replication. The mirror maker process will, however, retain and use the message key for partitioning so order is preserved on a per-key basis.
Here is an example showing how to mirror a single topic (named my-topic) from two input clusters:
> bin/kafka-run-class.sh kafka.tools.MirrorMaker --consumer.config consumer-1.properties --consumer.config consumer-2.properties --producer.config producer.properties --whitelist my-topic
Note that we specify the list of topics with the --whitelist option. This option allows any
regular expression using
Java-style regular
expressions. So you could mirror two topics named A and B using --whitelist 'A|B'. Or you
could mirror all topics using --whitelist '*'. Make sure to quote any regular expression to
ensure the shell doesn't try to expand it as a file path. For convenience we allow the use of ,
instead of | to specify a list of topics.
Sometime it is easier to say what it is that you don't want. Instead of using --whitelist to say
what you want to mirror you can use --blacklist to say what to exclude. This also takes a regular
expression argument.
Combining mirroring with the configuration auto.create.topics.enable=true makes it possible to
have a replica cluster that will automatically create and replicate all data in a source cluster
even as new topics are added.
Checking consumer position
Sometimes it's useful to see the position of your consumers. We have a tool that will show the position of all consumers in a consumer group as well as how far behind the end of the log they are. To run this tool on a consumer group named my-group consuming a topic named my-topic would look like this:
> bin/kafka-run-class.sh kafka.tools.ConsumerOffsetChecker --zkconnect localhost:2181 --group test Group Topic Pid Offset logSize Lag Owner my-group my-topic 0 0 0 0 test_jkreps-mn-1394154511599-60744496-0 my-group my-topic 1 0 0 0 test_jkreps-mn-1394154521217-1a0be913-0
Expanding your cluster
Adding servers to a Kafka cluster is easy, just assign them a unique broker id and start up Kafka on your new servers. However these new servers will not automatically be assigned any data partitions, so unless partitions are moved to them they won't be doing any work until new topics are created. So usually when you add machines to your cluster you will want to migrate some existing data to these machines.
The process of migrating data is manually initiated but fully automated. Under the covers what happens is that Kafka will add the new server as a follower of the partition it is migrating and allow it to fully replicate the existing data in that partition. When the new server has fully replicated the contents of this partition and joined the in-sync replica one of the existing replicas will delete their partition's data.
The partition reassignment tool can be used to move partitions across brokers. An ideal partition distribution would ensure even data load and partition sizes across all brokers. In 0.8.1, the partition reassignment tool does not have the capability to automatically study the data distribution in a Kafka cluster and move partitions around to attain an even load distribution. As such, the admin has to figure out which topics or partitions should be moved around.
The partition reassignment tool can run in 3 mutually exclusive modes -
- –generate: In this mode, given a list of topics and a list of brokers, the tool generates a candidate reassignment to move all partitions of the specified topics to the new brokers. This option merely provides a convenient way to generate a partition reassignment plan given a list of topics and target brokers.
- –execute: In this mode, the tool kicks off the reassignment of partitions based on the user provided reassignment plan. (using the –reassignment-json-file option). This can either be a custom reassignment plan hand crafted by the admin or provided by using the –generate option
- –verify: In this mode, the tool verifies the status of the reassignment for all partitions listed during the last –execute. The status can be either of successfully completed, failed or in progress
Automatically migrating data to new machines
The partition reassignment tool can be used to move some topics off of the current set of brokers to the newly added brokers. This is typically useful while expanding an existing cluster since it is easier to move entire topics to the new set of brokers, than moving one partition at a time. When used to do this, the user should provide a list of topics that should be moved to the new set of brokers and a target list of new brokers. The tool then evenly distributes all partitions for the given list of topics across the new set of brokers. During this move, the replication factor of the topic is kept constant. Effectively the replicas for all partitions for the input list of topics are moved from the old set of brokers to the newly added brokers.
For instance, the following example will move all partitions for topics foo1,foo2 to the new set of brokers 5,6. At the end of this move, all partitions for topics foo1 and foo2 will only exist on brokers 5,6
Since, the tool accepts the input list of topics as a json file, you first need to identify the topics you want to move and create the json file as follows-
> cat topics-to-move.json {"topics": [{"topic": "foo1"}, {"topic": "foo2"}], "version":1 }
Once the json file is ready, use the partition reassignment tool to generate a candidate assignment-
> bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 --topics-to-move-json-file
topics-to-move.json --broker-list "5,6" --generate Current partition replica assignment
{"version":1, "partitions":[{"topic":"foo1","partition":2,"replicas":[1,2]},
{"topic":"foo1","partition":0,"replicas":[3,4]}, {"topic":"foo2","partition":2,"replicas":[1,2]},
{"topic":"foo2","partition":0,"replicas":[3,4]}, {"topic":"foo1","partition":1,"replicas":[2,3]},
{"topic":"foo2","partition":1,"replicas":[2,3]}] }
Proposed partition reassignment configuration
{"version":1, "partitions":[{"topic":"foo1","partition":2,"replicas":[5,6]},
{"topic":"foo1","partition":0,"replicas":[5,6]}, {"topic":"foo2","partition":2,"replicas":[5,6]},
{"topic":"foo2","partition":0,"replicas":[5,6]}, {"topic":"foo1","partition":1,"replicas":[5,6]},
{"topic":"foo2","partition":1,"replicas":[5,6]}] }
The tool generates a candidate assignment that will move all partitions from topics foo1,foo2 to brokers 5,6. Note, however, that at this point, the partition movement has not started, it merely tells you the current assignment and the proposed new assignment. The current assignment should be saved in case you want to rollback to it. The new assignment should be saved in a json file (e.g. expand-cluster-reassignment.json) to be input to the tool with the –execute option as follows-
> bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 --reassignment-json-file
expand-cluster-reassignment.json --execute Current partition replica assignment
{"version":1, "partitions":[{"topic":"foo1","partition":2,"replicas":[1,2]},
{"topic":"foo1","partition":0,"replicas":[3,4]}, {"topic":"foo2","partition":2,"replicas":[1,2]},
{"topic":"foo2","partition":0,"replicas":[3,4]}, {"topic":"foo1","partition":1,"replicas":[2,3]},
{"topic":"foo2","partition":1,"replicas":[2,3]}] }
Save this to use as the --reassignment-json-file option during rollback Successfully started
reassignment of partitions {"version":1,
"partitions":[{"topic":"foo1","partition":2,"replicas":[5,6]},
{"topic":"foo1","partition":0,"replicas":[5,6]}, {"topic":"foo2","partition":2,"replicas":[5,6]},
{"topic":"foo2","partition":0,"replicas":[5,6]}, {"topic":"foo1","partition":1,"replicas":[5,6]},
{"topic":"foo2","partition":1,"replicas":[5,6]}] }
Finally, the –verify option can be used with the tool to check the status of the partition reassignment. Note that the same expand-cluster-reassignment.json (used with the –execute option) should be used with the –verify option
> bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 --reassignment-json-file expand-cluster-reassignment.json --verify Status of partition reassignment: Reassignment of partition [foo1,0] completed successfully Reassignment of partition [foo1,1] is in progress Reassignment of partition [foo1,2] is in progress Reassignment of partition [foo2,0] completed successfully Reassignment of partition [foo2,1] completed successfully Reassignment of partition [foo2,2] completed successfully
Custom partition assignment and migration
The partition reassignment tool can also be used to selectively move replicas of a partition to a specific set of brokers. When used in this manner, it is assumed that the user knows the reassignment plan and does not require the tool to generate a candidate reassignment, effectively skipping the –generate step and moving straight to the –execute step
For instance, the following example moves partition 0 of topic foo1 to brokers 5,6 and partition 1 of topic foo2 to brokers 2,3
The first step is to hand craft the custom reassignment plan in a json file-
> cat custom-reassignment.json
{"version":1,"partitions":[{"topic":"foo1","partition":0,"replicas":[5,6]},{"topic":"foo2","partition":1,"replicas":[2,3]}]}
Then, use the json file with the –execute option to start the reassignment process-
> bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 --reassignment-json-file
custom-reassignment.json --execute Current partition replica assignment
{"version":1, "partitions":[{"topic":"foo1","partition":0,"replicas":[1,2]},
{"topic":"foo2","partition":1,"replicas":[3,4]}] }
Save this to use as the --reassignment-json-file option during rollback Successfully started
reassignment of partitions {"version":1,
"partitions":[{"topic":"foo1","partition":0,"replicas":[5,6]},
{"topic":"foo2","partition":1,"replicas":[2,3]}] }
The –verify option can be used with the tool to check the status of the partition reassignment. Note that the same expand-cluster-reassignment.json (used with the –execute option) should be used with the –verify option
bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 --reassignment-json-file custom-reassignment.json --verify Status of partition reassignment: Reassignment of partition [foo1,0] completed successfully Reassignment of partition [foo2,1] completed successfully
Decommissioning brokers
The partition reassignment tool does not have the ability to automatically generate a reassignment plan for decommissioning brokers yet. As such, the admin has to come up with a reassignment plan to move the replica for all partitions hosted on the broker to be decommissioned, to the rest of the brokers. This can be relatively tedious as the reassignment needs to ensure that all the replicas are not moved from the decommissioned broker to only one other broker. To make this process effortless, we plan to add tooling support for decommissioning brokers in 0.8.2.
Increasing replication factor
Increasing the replication factor of an existing partition is easy. Just specify the extra replicas in the custom reassignment json file and use it with the –execute option to increase the replication factor of the specified partitions.
For instance, the following example increases the replication factor of partition 0 of topic foo from 1 to 3. Before increasing the replication factor, the partition's only replica existed on broker 5. As part of increasing the replication factor, we will add more replicas on brokers 6 and 7.
The first step is to hand craft the custom reassignment plan in a json file-
> cat increase-replication-factor.json {"version":1,
"partitions":[{"topic":"foo","partition":0,"replicas":[5,6,7]}]}
Then, use the json file with the –execute option to start the reassignment process-
> bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 --reassignment-json-file
increase-replication-factor.json --execute Current partition replica assignment
{"version":1, "partitions":[{"topic":"foo","partition":0,"replicas":[5]}]}
Save this to use as the --reassignment-json-file option during rollback Successfully started
reassignment of partitions {"version":1,
"partitions":[{"topic":"foo","partition":0,"replicas":[5,6,7]}]}
The –verify option can be used with the tool to check the status of the partition reassignment. Note that the same increase-replication-factor.json (used with the –execute option) should be used with the –verify option
bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 --reassignment-json-file increase-replication-factor.json --verify Status of partition reassignment: Reassignment of partition [foo,0] completed successfully
You can also verify the increase in replication factor with the kafka-topics tool-
> bin/kafka-topics.sh --zookeeper localhost:2181 --topic foo --describe Topic:foo PartitionCount:1 ReplicationFactor:3 Configs: Topic: foo Partition: 0 Leader: 5 Replicas: 5,6,7 Isr: 5,6,7
6.2 Datacenters
Some deployments will need to manage a data pipeline that spans multiple datacenters. Our recommended approach to this is to deploy a local Kafka cluster in each datacenter with application instances in each datacenter interacting only with their local cluster and mirroring between clusters (see the documentation on the mirror maker tool for how to do this).
This deployment pattern allows datacenters to act as independent entities and allows us to manage and tune inter-datacenter replication centrally. This allows each facility to stand alone and operate even if the inter-datacenter links are unavailable: when this occurs the mirroring falls behind until the link is restored at which time it catches up.
For applications that need a global view of all data you can use mirroring to provide clusters which have aggregate data mirrored from the local clusters in all datacenters. These aggregate clusters are used for reads by applications that require the full data set.
This is not the only possible deployment pattern. It is possible to read from or write to a remote Kafka cluster over the WAN, though obviously this will add whatever latency is required to get the cluster.
Kafka naturally batches data in both the producer and consumer so it can achieve high-throughput
even over a high-latency connection. To allow this though it may be necessary to increase the TCP
socket buffer sizes for the producer, consumer, and broker using the socket.send.buffer.bytes and
socket.receive.buffer.bytes configurations. The appropriate way to set this is documented
here.
It is generally not advisable to run a single Kafka cluster that spans multiple datacenters over a high-latency link. This will incur very high replication latency both for Kafka writes and ZooKeeper writes, and neither Kafka nor ZooKeeper will remain available in all locations if the network between locations is unavailable.
6.3 Kafka Configuration
Important Client Configurations
The most important producer configurations control
- compression
- sync vs async production
- batch size (for async producers)
The most important consumer configuration is the fetch size.
All configurations are documented in the configuration section.
A Production Server Config
Here is our server production server configuration:
# Replication configurations num.replica.fetchers=4 replica.fetch.max.bytes=1048576 replica.fetch.wait.max.ms=500 replica.high.watermark.checkpoint.interval.ms=5000 replica.socket.timeout.ms=30000 replica.socket.receive.buffer.bytes=65536 replica.lag.time.max.ms=10000 replica.lag.max.messages=4000 controller.socket.timeout.ms=30000 controller.message.queue.size=10 # Log configuration num.partitions=8 message.max.bytes=1000000 auto.create.topics.enable=true log.index.interval.bytes=4096 log.index.size.max.bytes=10485760 log.retention.hours=168 log.flush.interval.ms=10000 log.flush.interval.messages=20000 log.flush.scheduler.interval.ms=2000 log.roll.hours=168 log.retention.check.interval.ms=300000 log.segment.bytes=1073741824 # ZK configuration zookeeper.connection.timeout.ms=6000 zookeeper.sync.time.ms=2000 # Socket server configuration num.io.threads=8 num.network.threads=8 socket.request.max.bytes=104857600 socket.receive.buffer.bytes=1048576 socket.send.buffer.bytes=1048576 queued.max.requests=16 fetch.purgatory.purge.interval.requests=100 producer.purgatory.purge.interval.requests=100
Our client configuration varies a fair amount between different use cases.
Java Version
We're currently running JDK 1.7 u51, and we've switched over to the G1 collector. If you do this (and we highly recommend it), make sure you're on u51. We tried out u21 in testing, but we had a number of problems with the GC implementation in that version. Our tuning looks like this:
-Xms4g -Xmx4g -XX:PermSize=48m -XX:MaxPermSize=48m -XX:+UseG1GC XX:MaxGCPauseMillis=20 --XX:InitiatingHeapOccupancyPercent=35
For reference, here are the stats on one of LinkedIn's busiest clusters (at peak): - 15 brokers - 15.5k partitions (replication factor 2) - 400k messages/sec in - 70 MB/sec inbound, 400 MB/sec+ outbound The tuning looks fairly aggressive, but all of the brokers in that cluster have a 90% GC pause time of about 21ms, and they're doing less than 1 young GC per second.
6.4 Hardware and OS
We are using dual quad-core Intel Xeon machines with 24GB of memory.
You need sufficient memory to buffer active readers and writers. You can do a back-of-the-envelope estimate of memory needs by assuming you want to be able to buffer for 30 seconds and compute your memory need as write_throughput*30.
The disk throughput is important. We have 8x7200 rpm SATA drives. In general disk throughput is the performance bottleneck, and more disks is more better. Depending on how you configure flush behavior you may or may not benefit from more expensive disks (if you force flush often then higher RPM SAS drives may be better).
OS
Kafka should run well on any unix system and has been tested on Linux and Solaris.
We have seen a few issues running on Windows and Windows is not currently a well supported platform though we would be happy to change that.
You likely don't need to do much OS-level tuning though there are a few things that will help performance.
Two configurations that may be important:
- We upped the number of file descriptors since we have lots of topics and lots of connections.
- We upped the max socket buffer size to enable high-performance data transfer between data centers described described here.
Disks and Filesystem
We recommend using multiple drives to get good throughput and not sharing the same drives used for Kafka data with application logs or other OS filesystem activity to ensure good latency. As of 0.8 you can either RAID these drives together into a single volume or format and mount each drive as its own directory. Since Kafka has replication the redundancy provided by RAID can also be provided at the application level. This choice has several tradeoffs.
If you configure multiple data directories partitions will be assigned round-robin to data directories. Each partition will be entirely in one of the data directories. If data is not well balanced among partitions this can lead to load imbalance between disks.
RAID can potentially do better at balancing load between disks (although it doesn't always seem to) because it balances load at a lower level. The primary downside of RAID is that it is usually a big performance hit for write throughput and reduces the available disk space.
Another potential benefit of RAID is the ability to tolerate disk failures. However our experience has been that rebuilding the RAID array is so I/O intensive that it effectively disables the server, so this does not provide much real availability improvement.
Application vs. OS Flush Management
Kafka always immediately writes all data to the filesystem and supports the ability to configure the flush policy that controls when data is forced out of the OS cache and onto disk using the and flush. This flush policy can be controlled to force data to disk after a period of time or after a certain number of messages has been written. There are several choices in this configuration.
Kafka must eventually call fsync to know that data was flushed. When recovering from a crash for any log segment not known to be fsync'd Kafka will check the integrity of each message by checking its CRC and also rebuild the accompanying offset index file as part of the recovery process executed on startup.
Note that durability in Kafka does not require syncing data to disk, as a failed node will always recover from its replicas.
We recommend using the default flush settings which disable application fsync entirely. This means relying on the background flush done by the OS and Kafka's own background flush. This provides the best of all worlds for most uses: no knobs to tune, great throughput and latency, and full recovery guarantees. We generally feel that the guarantees provided by replication are stronger than sync to local disk, however the paranoid still may prefer having both and application level fsync policies are still supported.
The drawback of using application level flush settings are that this is less efficient in it's disk usage pattern (it gives the OS less leeway to re-order writes) and it can introduce latency as fsync in most Linux filesystems blocks writes to the file whereas the background flushing does much more granular page-level locking.
In general you don't need to do any low-level tuning of the filesystem, but in the next few sections we will go over some of this in case it is useful.
Understanding Linux OS Flush Behavior
In Linux, data written to the filesystem is maintained in pagecache until it must be written out to disk (due to an application-level fsync or the OS's own flush policy). The flushing of data is done by a set of background threads called pdflush (or in post 2.6.32 kernels "flusher threads").
Pdflush has a configurable policy that controls how much dirty data can be maintained in cache and for how long before it must be written back to disk. This policy is described here. When Pdflush cannot keep up with the rate of data being written it will eventually cause the writing process to block incurring latency in the writes to slow down the accumulation of data.
You can see the current state of OS memory usage by doing
> cat /proc/meminfo
The meaning of these values are described in the link above.
Using pagecache has several advantages over an in-process cache for storing data that will be written out to disk:
- The I/O scheduler will batch together consecutive small writes into bigger physical writes which improves throughput.
- The I/O scheduler will attempt to re-sequence writes to minimize movement of the disk head which improves throughput.
- It automatically uses all the free memory on the machine
Ext4 Notes
Ext4 may or may not be the best filesystem for Kafka. Filesystems like XFS supposedly handle locking during fsync better. We have only tried Ext4, though.
It is not necessary to tune these settings, however those wanting to optimize performance have a few knobs that will help:
- data=writeback: Ext4 defaults to data=ordered which puts a strong order on some writes. Kafka does not require this ordering as it does very paranoid data recovery on all unflushed log. This setting removes the ordering constraint and seems to significantly reduce latency.
- Disabling journaling: Journaling is a tradeoff: it makes reboots faster after server crashes but it introduces a great deal of additional locking which adds variance to write performance. Those who don't care about reboot time and want to reduce a major source of write latency spikes can turn off journaling entirely.
- commit=num_secs: This tunes the frequency with which ext4 commits to its metadata journal. Setting this to a lower value reduces the loss of unflushed data during a crash. Setting this to a higher value will improve throughput.
- nobh: This setting controls additional ordering guarantees when using data=writeback mode. This should be safe with Kafka as we do not depend on write ordering and improves throughput and latency.
- delalloc: Delayed allocation means that the filesystem avoid allocating any blocks until the physical write occurs. This allows ext4 to allocate a large extent instead of smaller pages and helps ensure the data is written sequentially. This feature is great for throughput. It does seem to involve some locking in the filesystem which adds a bit of latency variance.
6.5 Monitoring
Kafka uses Yammer Metrics for metrics reporting in both the server and the client. This can be configured to report stats using pluggable stats reporters to hook up to your monitoring system.
The easiest way to see the available metrics to fire up jconsole and point it at a running kafka client or server; this will all browsing all metrics with JMX.
We pay particular we do graphing and alerting on the following metrics:
Broker monitoring
Message in rate
- Mbean name
kafka.server:type=BrokerTopicMetrics,name=MessagesInPerSec- Normal value
Byte in rate
- Mbean name
kafka.server:type=BrokerTopicMetrics,name=BytesInPerSec- Normal value
Request rate
- Mbean name
kafka.network:type=RequestMetrics,name=RequestsPerSec,request={Produce|FetchConsumer|FetchFollower}- Normal value
Byte out rate
- Mbean name
kafka.server:type=BrokerTopicMetrics,name=BytesOutPerSec- Normal value
Log flush rate and time
- Mbean name
kafka.log:type=LogFlushStats,name=LogFlushRateAndTimeMs- Normal value
# of under replicated partitions (|ISR| < |all replicas|)
- Mbean name
kafka.server:type=ReplicaManager,name=UnderReplicatedPartitions- Normal value
- 0
Is controller active on broker
- Mbean name
kafka.controller:type=KafkaController,name=ActiveControllerCount- Normal value
- only one broker in the cluster should have 1
Leader election rate
- Mbean name
kafka.controller:type=ControllerStats,name=LeaderElectionRateAndTimeMs- Normal value
- non-zero when there are broker failures
Unclean leader election rate
- Mbean name
kafka.controller:type=ControllerStats,name=UncleanLeaderElectionsPerSec- Normal value
- 0
Partition counts
- Mbean name
kafka.server:type=ReplicaManager,name=PartitionCount- Normal value
- mostly even across brokers
Leader replica counts
- Mbean name
kafka.server:type=ReplicaManager,name=LeaderCount- Normal value
- mostly even across brokers
ISR shrink rate
- Mbean name
kafka.server:type=ReplicaManager,name=IsrShrinksPerSec- Normal value
- If a broker goes down, ISR for some of the partitions will shrink. When that broker is up again, ISR will be expanded once the replicas are fully caught up. Other than that, the expected value for both ISR shrink rate and expansion rate is 0.
ISR expansion rate
- Mbean name
kafka.server:type=ReplicaManager,name=IsrExpandsPerSec- Normal value
- See above
Max lag in messages btw follower and leader replicas
- Mbean name
kafka.server:type=ReplicaFetcherManager,name=MaxLag,clientId=Replica- Normal value
- < replica.lag.max.messages
Lag in messages per follower replica
- Mbean name
kafka.server:type=FetcherLagMetrics,name=ConsumerLag,clientId=([-.\w]+),topic=([-.\w]+),partition=([0-9]+)- Normal value
- < replica.lag.max.messages
Requests waiting in the producer purgatory
- Mbean name
kafka.server:type=ProducerRequestPurgatory,name=PurgatorySize- Normal value
- non-zero if ack=-1 is used
Requests waiting in the fetch purgatory
- Mbean name
kafka.server:type=FetchRequestPurgatory,name=PurgatorySize- Normal value
- size depends on fetch.wait.max.ms in the consumer
Request total time
- Mbean name
kafka.network:type=RequestMetrics,name=TotalTimeMs,request={Produce|FetchConsumer|FetchFollower}- Normal value
- broken into queue, local, remote and response send time
Time the request waiting in the request queue
- Mbean name
kafka.network:type=RequestMetrics,name=QueueTimeMs,request={Produce|FetchConsumer|FetchFollower}- Normal value
Time the request being processed at the leader
- Mbean name
kafka.network:type=RequestMetrics,name=LocalTimeMs,request={Produce|FetchConsumer|FetchFollower}- Normal value
Time the request waits for the follower
- Mbean name
kafka.network:type=RequestMetrics,name=RemoteTimeMs,request={Produce|FetchConsumer|FetchFollower}- Normal value
- non-zero for produce requests when ack=-1
Time to send the response
- Mbean name
kafka.network:type=RequestMetrics,name=ResponseSendTimeMs,request={Produce|FetchConsumer|FetchFollower}- Normal value
Number of messages the consumer lags behind the producer by
- Mbean name
kafka.consumer:type=ConsumerFetcherManager,name=MaxLag,clientId=([-.\w]+)- Normal value
The average fraction of time the network processors are idle
- Mbean name
kafka.network:type=SocketServer,name=NetworkProcessorAvgIdlePercent- Normal value
- between 0 and 1, ideally > 0.3
The average fraction of time the request handler threads are idle
- Mbean name
kafka.server:type=KafkaRequestHandlerPool,name=RequestHandlerAvgIdlePercent- Normal value
- between 0 and 1, ideally > 0.3
New producer monitoring
The following metrics are available on new producer instances.
waiting-threads
- Mbean name
kafka.producer:type=producer-metrics,client-id=([-.\w]+)- Description
- The number of user threads blocked waiting for buffer memory to enqueue their records
buffer-total-bytes
- Mbean name
kafka.producer:type=producer-metrics,client-id=([-.\w]+)- Description
- The maximum amount of buffer memory the client can use (whether or not it is currently used).
buffer-available-bytes
- Mbean name
kafka.producer:type=producer-metrics,client-id=([-.\w]+)- Description
- The total amount of buffer memory that is not being used (either unallocated or in the free list).
bufferpool-wait-time
- Mbean name
kafka.producer:type=producer-metrics,client-id=([-.\w]+)- Description
- The fraction of time an appender waits for space allocation.
batch-size-avg
- Mbean name
kafka.producer:type=producer-metrics,client-id=([-.\w]+)- Description
- The average number of bytes sent per partition per-request.
batch-size-max
- Mbean name
kafka.producer:type=producer-metrics,client-id=([-.\w]+)- Description
- The max number of bytes sent per partition per-request.
compression-rate-avg
- Mbean name
kafka.producer:type=producer-metrics,client-id=([-.\w]+)- Description
- The average compression rate of record batches.
record-queue-time-avg
- Mbean name
kafka.producer:type=producer-metrics,client-id=([-.\w]+)- Description
- The average time in ms record batches spent in the record accumulator.
record-queue-time-max
- Mbean name
kafka.producer:type=producer-metrics,client-id=([-.\w]+)- Description
- The maximum time in ms record batches spent in the record accumulator
request-latency-avg
- Mbean name
kafka.producer:type=producer-metrics,client-id=([-.\w]+)- Description
- The average request latency in ms
request-latency-max
- Mbean name
kafka.producer:type=producer-metrics,client-id=([-.\w]+)- Description
- The maximum request latency in ms
record-send-rate
- Mbean name
kafka.producer:type=producer-metrics,client-id=([-.\w]+)- Description
- The average number of records sent per second.
records-per-request-avg
- Mbean name
kafka.producer:type=producer-metrics,client-id=([-.\w]+)- Description
- The average number of records per request.
record-retry-rate
- Mbean name
kafka.producer:type=producer-metrics,client-id=([-.\w]+)- Description
- The average per-second number of retried record sends
record-error-rate
- Mbean name
kafka.producer:type=producer-metrics,client-id=([-.\w]+)- Description
- The average per-second number of record sends that resulted in errors
record-size-max
- Mbean name
kafka.producer:type=producer-metrics,client-id=([-.\w]+)- Description
- The maximum record size
record-size-avg
- Mbean name
kafka.producer:type=producer-metrics,client-id=([-.\w]+)- Description
- The average record size
requests-in-flight
- Mbean name
kafka.producer:type=producer-metrics,client-id=([-.\w]+)- Description
- The current number of in-flight requests awaiting a response.
metadata-age
- Mbean name
kafka.producer:type=producer-metrics,client-id=([-.\w]+)- Description
- The age in seconds of the current producer metadata being used.
connection-close-rate
- Mbean name
kafka.producer:type=producer-metrics,client-id=([-.\w]+)- Description
- Connections closed per second in the window.
connection-creation-rate
- Mbean name
kafka.producer:type=producer-metrics,client-id=([-.\w]+)- Description
- New connections established per second in the window.
network-io-rate
- Mbean name
kafka.producer:type=producer-metrics,client-id=([-.\w]+)- Description
- The average number of network operations (reads or writes) on all connections per second.
outgoing-byte-rate
- Mbean name
kafka.producer:type=producer-metrics,client-id=([-.\w]+)- Description
- The average number of outgoing bytes sent per second to all servers.
request-rate
- Mbean name
kafka.producer:type=producer-metrics,client-id=([-.\w]+)- Description
- The average number of requests sent per second.
request-size-avg
- Mbean name
kafka.producer:type=producer-metrics,client-id=([-.\w]+)- Description
- The average size of all requests in the window.
request-size-max
- Mbean name
kafka.producer:type=producer-metrics,client-id=([-.\w]+)- Description
- The maximum size of any request sent in the window.
incoming-byte-rate
- Mbean name
kafka.producer:type=producer-metrics,client-id=([-.\w]+)- Description
- Bytes/second read off all sockets
response-rate
- Mbean name
kafka.producer:type=producer-metrics,client-id=([-.\w]+)- Description
- Responses received sent per second.
select-rate
- Mbean name
kafka.producer:type=producer-metrics,client-id=([-.\w]+)- Description
- Number of times the I/O layer checked for new I/O to perform per second
io-wait-time-ns-avg
- Mbean name
kafka.producer:type=producer-metrics,client-id=([-.\w]+)- Description
- The average length of time the I/O thread spent waiting for a socket ready for reads or writes in nanoseconds.
io-wait-ratio
- Mbean name
kafka.producer:type=producer-metrics,client-id=([-.\w]+)- Description
- The fraction of time the I/O thread spent waiting.
io-time-ns-avg
- Mbean name
kafka.producer:type=producer-metrics,client-id=([-.\w]+)- Description
- The average length of time for I/O per select call in nanoseconds.
io-ratio
- Mbean name
kafka.producer:type=producer-metrics,client-id=([-.\w]+)- Description
- The fraction of time the I/O thread spent doing I/O
connection-count
- Mbean name
kafka.producer:type=producer-metrics,client-id=([-.\w]+)- Description
- The current number of active connections.
outgoing-byte-rate
- Mbean name
kafka.producer:type=producer-node-metrics,client-id=([-.\w]+),node-id=([0-9]+)- Description
- The average number of outgoing bytes sent per second for a node.
request-rate
- Mbean name
kafka.producer:type=producer-node-metrics,client-id=([-.\w]+),node-id=([0-9]+)- Description
- The average number of requests sent per second for a node.
request-size-avg
- Mbean name
kafka.producer:type=producer-node-metrics,client-id=([-.\w]+),node-id=([0-9]+)- Description
- The average size of all requests in the window for a node.
request-size-max
- Mbean name
kafka.producer:type=producer-node-metrics,client-id=([-.\w]+),node-id=([0-9]+)- Description
- The maximum size of any request sent in the window for a node.
incoming-byte-rate
- Mbean name
kafka.producer:type=producer-node-metrics,client-id=([-.\w]+),node-id=([0-9]+)- Description
- The average number of responses received per second for a node.
request-latency-avg
- Mbean name
kafka.producer:type=producer-node-metrics,client-id=([-.\w]+),node-id=([0-9]+)- Description
- The average request latency in ms for a node.
request-latency-max
- Mbean name
kafka.producer:type=producer-node-metrics,client-id=([-.\w]+),node-id=([0-9]+)- Description
- The maximum request latency in ms for a node.
response-rate
- Mbean name
kafka.producer:type=producer-node-metrics,client-id=([-.\w]+),node-id=([0-9]+)- Description
- Responses received sent per second for a node.
record-send-rate
- Mbean name
kafka.producer:type=producer-topic-metrics,client-id=([-.\w]+),topic=([-.\w]+)- Description
- The average number of records sent per second for a topic.
byte-rate
- Mbean name
kafka.producer:type=producer-topic-metrics,client-id=([-.\w]+),topic=([-.\w]+)- Description
- The average number of bytes sent per second for a topic.
compression-rate
- Mbean name
kafka.producer:type=producer-topic-metrics,client-id=([-.\w]+),topic=([-.\w]+)- Description
- The average compression rate of record batches for a topic.
record-retry-rate
- Mbean name
kafka.producer:type=producer-topic-metrics,client-id=([-.\w]+),topic=([-.\w]+)- Description
- The average per-second number of retried record sends for a topic
record-error-rate
- Mbean name
kafka.producer:type=producer-topic-metrics,client-id=([-.\w]+),topic=([-.\w]+)- Description
- The average per-second number of record sends that resulted in errors for a topic.
We recommend monitor GC time and other stats and various server stats such as CPU utilization, I/O service time, etc. On the client side, we recommend monitor the message/byte rate (global and per topic), request rate/size/time, and on the consumer side, max lag in messages among all partitions and min fetch request rate. For a consumer to keep up, max lag needs to be less than a threshold and min fetch rate needs to be larger than 0.
Audit
The final alerting we do is on the correctness of the data delivery. We audit that every message that is sent is consumed by all consumers and measure the lag for this to occur. For important topics we alert if a certain completeness is not achieved in a certain time period. The details of this are discussed in KAFKA-260.
6.6 ZooKeeper
Stable version
At LinkedIn, we are running ZooKeeper 3.3.*. Version 3.3.3 has known serious issues regarding ephemeral node deletion and session expirations. After running into those issues in production, we upgraded to 3.3.4 and have been running that smoothly for over a year now.
Operationalizing ZooKeeper
Operationally, we do the following for a healthy ZooKeeper installation:
- Redundancy in the physical/hardware/network layout: try not to put them all in the same rack, decent (but don't go nuts) hardware, try to keep redundant power and network paths, etc.
- I/O segregation: if you do a lot of write type traffic you'll almost definitely want the transaction logs on a different disk group than application logs and snapshots (the write to the ZooKeeper service has a synchronous write to disk, which can be slow).
- Application segregation: Unless you really understand the application patterns of other apps that you want to install on the same box, it can be a good idea to run ZooKeeper in isolation (though this can be a balancing act with the capabilities of the hardware).
- Use care with virtualization: It can work, depending on your cluster layout and read/write patterns and SLAs, but the tiny overheads introduced by the virtualization layer can add up and throw off ZooKeeper, as it can be very time sensitive
- ZooKeeper configuration and monitoring: It's java, make sure you give it 'enough' heap space (We usually run them with 3-5G, but that's mostly due to the data set size we have here). Unfortunately we don't have a good formula for it. As far as monitoring, both JMZ and the 4 letter commands are very useful, they do overlap in some cases (and in those cases we prefer the 4 letter commands, they seem more predictable, or at the very least, they work better with the LI monitoring infrastructure)
- Don't overbuild the cluster: large clusters, especially in a write heavy usage pattern, means a lot of intracluster communication (quorums on the writes and subsequent cluster member updates), but don't underbuild it (and risk swamping the cluster).
- Try to run on a 3-5 node cluster: ZooKeeper writes use quorums and inherently that means having an odd number of machines in a cluster. Remember that a 5 node cluster will cause writes to slow down compared to a 3 node cluster, but will allow more fault tolerance.
Overall, we try to keep the ZooKeeper system as small as will handle the load (plus standard growth capacity planning) and as simple as possible. We try not to do anything fancy with the configuration or application layout as compared to the official release as well as keep it as self contained as possible. For these reasons, we tend to skip the OS packaged versions, since it has a tendency to try to put things in the OS standard hierarchy, which can be 'messy', for want of a better way to word it.

Footnotes:
(訳注) 警告は無視してよさそうです。 0.8.3で修正される見込みのようです 。
(訳注) 0.8.2 のリリースにconsumerも一部既に含まれていますが、正式には 0.9 で利用可能なようです( RE: Java Consumer API 、 Re: Consumer in Java client )
(訳注) 関連ソース ConsumerConnector 、KafkaStream 、 MessageAndMetadata
(訳注) 関連ソース SimpleConsumer 、 FetchRequest 、 FetchResponse 、 TopicMetadataRequest 、 TopicMetadataResponse 、OffsetRequest 、OffsetResponse
(訳注) 関連 issue KAFKA-1092
(訳注) log_dirs に、 <トピック名>-<パーティション番号>/000...000.log の様に保存されています。
(訳注) 何言ってんのかよく分かんない
(訳注) 何言ってんのかよく分かんない
(訳注) ここがそのトピック毎の設定なんだけど…。ブローカ設定と入れ違ったかな?
(訳注) ブローカ設定の項の説明と一字一句違わない
(訳注) 実際は、このプロパティに対応するサーバデフォルトプロパティは無い。その為、利用する際は必ずトピックレベルで設定すること。
(訳注) この記述は古いそうです。参考スレッド Re: New producer in production
(訳注) New Producerの場合は acks
(訳注) 関係ありそうなコード https://github.com/apache/kafka/blob/0.8.2.1/core/src/main/scala/kafka/log/LogManager.scala#L119-L127 https://github.com/apache/kafka/blob/0.8.2.1/core/src/main/scala/kafka/log/Log.scala#L191-L219 https://github.com/apache/kafka/blob/0.8.2.1/core/src/main/scala/kafka/message/Message.scala#L159